Organizations that use hundreds of SaaS applications typically have to either purchase another to manage their software spend or build an in-house solution that aims to achieve similar results.
However, our recently-released License Optimization Accelerator*, which comes as a customizable, pre-packaged solution, now gives organizations a 3rd option for managing SaaS spend.
To help you better understand the automation accelerator and whether it’s the right solution for your business, I’ll walk you through how my team thought about and executed it. But to begin, let’s review how, exactly, the accelerator works.
* Our accelerators are pre-packaged, customizable solutions that come with pre-built recipes, instructional guides, solution components, reference data, and more. We offer a comprehensive library of accelerators—in addition to the License Optimization Accelerator—so that you can easily and quickly leverage automation in any process. To discover and learn about all of the accelerators we currently provide, you can visit this page.
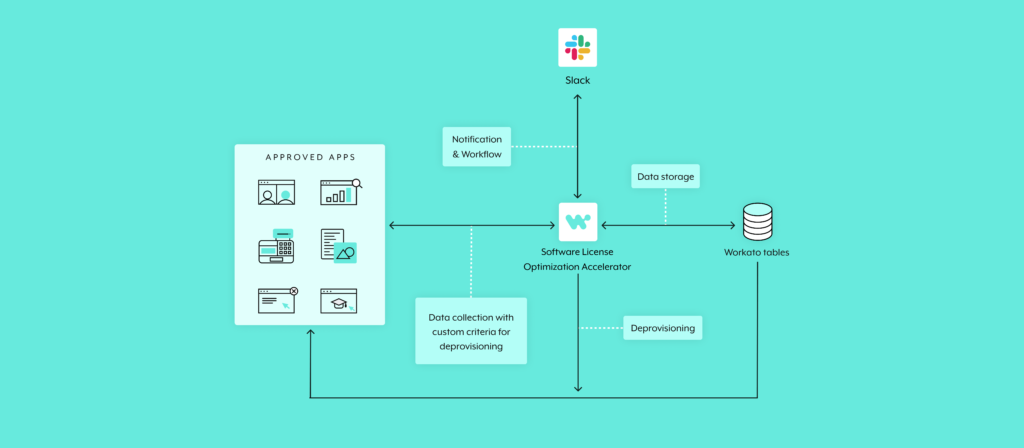
Overview on the License Optimization Accelerator
Here are the features we’ve included in the accelerator:
- Scheduler: It allows you to run the optimization process on a customized schedule, per application.

- Discovery Engine: It collects the applications’ usage data, calculates their utilization scores, and generates recommendations to optimize (remove) licenses for users.
- Optimization Engine: It has a User Approval Workflow, Reminders and Notifications, and the final Optimization Actions functionality—all of which let you optimize based on the recommendations from the Discovery Engine.

- Administration and Monitoring: This allows you to maintain the accelerator, as well as trace and monitor jobs as needed.
The core design principles of our License Optimization Accelerator (and of our accelerators more broadly)
There are typically six factors we consider when implementing any accelerator:

Let’s review each within the context of our License Optimization Accelerator.
1. Modular
The first step is to understand the ‘domains’, or the specific areas we need to solve for. By starting here, we’ll be able to better decide how we modularize our recipes and functions. Another benefit of a modularized design is that it allows us to easily add or replace functionality and reuse common functions where possible.
Embracing modularity in the License Optimization Accelerator
The applications each organization uses will undoubtedly vary. Knowing this, our accelerator would need to adapt to any organization’s tech stack and allow clients to configure rules-based recommendations for a given application.
For instance, Company A may want to downgrade Zoom Pro licenses for users who haven’t hosted meetings over the past 30 days; whereas Company B only wants to downgrade licenses for users who have spent less than 100 minutes in Zoom meetings over the past 20 days.
Now, imagine multiple applications with differing optimization criteria (which determines the utilization score) across organizations. How do we model a unified Discovery Engine that can be easily adopted by each organization and customized to their needs? By using three main modules: data collection, calculation, and recommendation.

Data collection can occur either by using the applications’ APIs or files. We designed these as individual functions. That way, we can easily add more functions if we want to collect data using APIs, or we can reuse the CSV Processor function for any application by merely configuring the file format, among other details.
The Calculation and Recommendation functions, on the other hand, are driven by different criteria for different applications. By deriving a common formula for calculations, we can now configure the criteria per application and use the same functions.
2. Extensible
Since organizations have a varied tech stack, we needed to consider an approach where applications can be onboarded easily. More specifically, we needed to collect rich data on application utilization based on specific criteria for each app.
For example, if we use a gift-giving platform like Sendoso, we might want to consider users who have not sent any gifts in the past 30 days for optimization; whereas in the case of a collaboration and work management app like Smartsheet, we might want to find (and optimize) all users who don’t own sheets or haven’t logged into the app over the past 30 days.
Knowing this, here’s what we did:
Most applications have an admin portal which allows the admin to download a ‘Usage Report’. These reports are standard CSV reports and will have more data around the usage of the application. With this in mind, we designed a generic data collection function for processing CSV reports. Since the data we need to collect is based on the application and CSV headers, these can be configured in a table to keep the CSV processor function generic.

With this solution, an organization wanting to onboard more apps has two options: either add more functions to collect data using an available API, or simply configure the CSV file format for each application and let the accelerator take care of the rest!
3. Customizable
The User Approval Workflow has to be implemented in a way that allows the accelerator to capture the response from these users. To help enable this functionality, we chose to use Workbot for Slack, but the technology you use and your levels of approval could vary.
The User Approval Workflow is designed to have the Slack functionality in a separate set of functions. This allows organizations that use Microsoft Teams to easily swap to the MS Teams Workbot.
Additionally, the level of approval is also controlled using properties. That way, organizations that want to skip the manager approval can simply disable a property and use a 2-Level approval workflow instead.

4. Asynchronous
The orchestration process from scheduler to discovery (collection, calculation, recommendation) and optimization (approvals, alerts, and actions) could be long running, and it can span multiple functions, depending on the number of applications you onboard.
For example, let’s consider a flow that uses two applications (Salesforce and Sendoso CSV Reports). The process flow would look something like this:

Here, in case any functionality runs even as a partial success (for example, if one data collection function fails, but the other collects the data), we still want to continue the process and notify an admin on the failures/warnings.
The challenge in designing these functions as asynchronous is not knowing what the actual state of the process was after each call. Let’s assume we want to continue to do calculations of the score if the Collection ran with Success or Partial Success. But how can the Discover Engine Orchestration know if Collection ran successfully or failed completely?
To solve this, we added a table where the job is logged for each function. The parent job id of the scheduler is propagated to all sub functions in order to log a child job with reference to the parent job. This allows us to have an asynchronous mode of communication, while being able to track the end-to-end process by using the job id of each child process.
An additional benefit of this approach is that since the job details were logged into a table, the main scheduler can do the final error notification even if any child job fails, has errors, or shows a warning.
5. Loose coupling and high cohesion
While designing an accelerator, we have to consider all of the ways in which it needs to be extended in order to fit our customers’ needs.
We want to give the guidelines around those changes, including how they can achieve it by either using extra functions that can be plugged in or by changing only relevant functions. Essentially, we want to minimize the impact of these changes on the calling functions.
For this release, we chose to use Workato Lookups as the tables for Configurations as well as Data Storage. This means that customers who decide to move the ‘data’ tables to a database should be able to easily modify the functions to make necessary changes.
To achieve this, we designed a set of wrapper functions for these data tables called Data Access Functions. These functions perform CRUD operations on the tables, and any core functions can make use of these. In essence, the technology used for tables is itself decoupled from the core functions, and changes to these tables only need to be performed within the wrapper functions.

6. Configurable
While working on this accelerator, we also had to consider the fact that different organizations will have different process flows or choices of technologies. As a result, we’ve allowed toggling of features using properties.
For example, the User Approval Workflow, Manager Approval, or a Test Mode (to redirect Slack or email messages during the development/testing phase) can be toggled on or off using properties—giving organizations the flexibility to design their process according to their needs.
Final thoughts
This accelerator is intended to help organizations move quickly in designing and implementing a best-in-class solution for managing software spend. And given how customizable and extendable it is, we’re confident that you can make it your own.
To learn more about our License Optimization Accelerator, you can reach out to your CSM or to our team at accelerators.feedback@workato.com.