
Late last week, collaboration app Slack experienced a three-hour outage that affected some of their users. Though the outage was fairly short, it inspired satirical articles about how devastating life was without the app – not surprising, considering that Slack has 8.8 million daily users.
Last week’s Slack outage calls to mind perennial concerns about new tools and technology. When it comes to embracing new tech, businesses do and should have a healthy level of skepticism, especially when it comes to reliability.
But the SaaS industry has made great strides in the past few years to counteract and even prevent outages and improve reliability. Here are a few reasons why SaaS companies deserve our trust now more than ever.
Long-Term Uptime Is Phenomenal
The most common metric for evaluating reliability is uptime: the percentage of time that a product or service was available and usable, with no hiccups. Today, SaaS companies boast almost unbelievable uptimes; the industry benchmark is >99.99%. That’s a ridiculously solid number. In fact, your car probably breaks down more frequently!
In a world where >99.9% uptime is a baseline expectation, it can be easy to take any drop in uptime as a sign that a platform or service isn’t as reliable as it ought to be. But it’s important to look at the bigger picture: what does long-term uptime look like? Many companies do a great job over the long-term; for example, last week’s Slack outage was only the fourth time that Slack’s monthly uptime dipped below 99.9% in five whole years!
Providers Are Taking Preparation Seriously
While uptime matters, what matters more is how providers handle incidents themselves. Today, SaaS companies, service providers, and websites are more prepared than ever to resolve—and prevent—major disruptions to service.
One common approach is to enlist specialized firms to help plan for and create protocols for disruptions. In early March, for example, GitHub survived the biggest distributed denial of service (DDoS) attack ever recorded. During the attack, 1.35 terabits of traffic hit the platform—per second.
The attack was fended off by Akamai Prolexic, a DDoS mitigation service that can be automatically invoked in the event of an attack. After just eight minutes, the attack abated.
By leveraging the help of DDoS mitigation experts, GitHub was able to withstand what could have otherwise been a catastrophic disruption for its users. And because DDoS attacks are Prolexic’s specialty, GitHub also benefited from their expert foresight: prior to the attack, the firm had adopted protocols to mitigate an emerging type of DDoS attacks known as memcached attacks—the exact type of attack that GitHub later faced.
Similarly, when it comes to preparing for the strain that rapid growth can create, SaaS companies are boosting reliability by implementing chaos engineering, which focuses on controlled stress testing so companies can identify potential problems before they occur.
This type of anticipatory planning and incident simulation has become increasingly common, and not just among business apps. In 2016, Netflix tested its ability to withstand an unorthodox type of DDoS attack. They then released two open-source tools that developers can use to identify vulnerabilities through similar testing. And they’re not alone; no matter the product, tech companies around the world are working to give their customers reliable, excellent experiences.
Companies Have Committed to Radically Transparent Communication
In any crisis, knowledge is power. These days, customers expect tech companies to be transparent and communicative about service issues—and companies are rising to meet that bar.
In January of 2017, for example, a systems admin at GitLab accidentally deleted the primary database while trying to fix a site slowdown. The company restored a six-hour-old backup, but any data created in the following six hours was permanently lost.

Instead of spinning the incident or shifting the blame, GitLab used the crisis as a chance to demonstrate their honesty. The transparency worked; users lauded the company’s straightforwardness and even wished them luck in fixing the problem.
Likewise, a radically honest approach to crisis management helped Instapaper, an app that allows users to save web content for later consumption, actually win over new users in the aftermath of an outage.
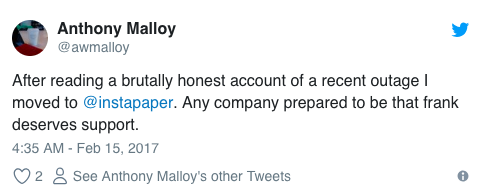
Thanks to examples like these, SaaS companies have learned that honesty is the best policy, and they’re handling service disruptions accordingly.
In the end, businesses (and individual users as well) will never stop worrying about the reliability of the technology they use. After all, technology has become one of the primary ways we interact with each other and the world; it’s only right that we expect it to work.
Tech companies aren’t oblivious to this burden. They’re actively working and collaborating to improve reliability and build trust with their users—even in the worst of situations.
Loved this article? Read more about chat apps and the future of work.