Your employees often view the same set of data across different applications.
Your marketers might view leads in a marketing automation platform while your sales reps view them in a CRM; your HR team might track employee information in an HRIS while IT tracks it in an ITSM; your finance team might review sales orders in an ERP system while your customer-facing employees review them in a CRM—and the list of examples go on.
Having the same record types appear across applications is clearly essential, but the process of manually re-entering data in applications leaves employees prone to errors that create data discrepancies between systems.
This results in misalignment and friction among functions, individual teams being misled into making poor decisions, and business-critical reports becoming inaccurate. Given these consequences, it’s perhaps little surprise that poor data quality costs organizations approximately $3.1 trillion every year in the United States.
Data synchronization neatly addresses this issue, as it all but ensures that the data across your apps is consistent and accurate—assuming you’re working with error-free source systems.
To give you a complete understanding of data synchronization, we’ll define it, highlight common examples, explore its benefits, and explain how to implement it.

Implement data syncs with ease by using Workato
Workato, the leader in enterprise automation, lets you implement data syncs without having to write a single line of code.
Data synchronization definition
Data synchronization, or data sync, is the continual process of keeping a record type identical between two or more systems. This can be done in real-time, in near real-time, or in batches.

Types of data synchronization
Your synchronization process can work in one of two ways:
One-way data sync
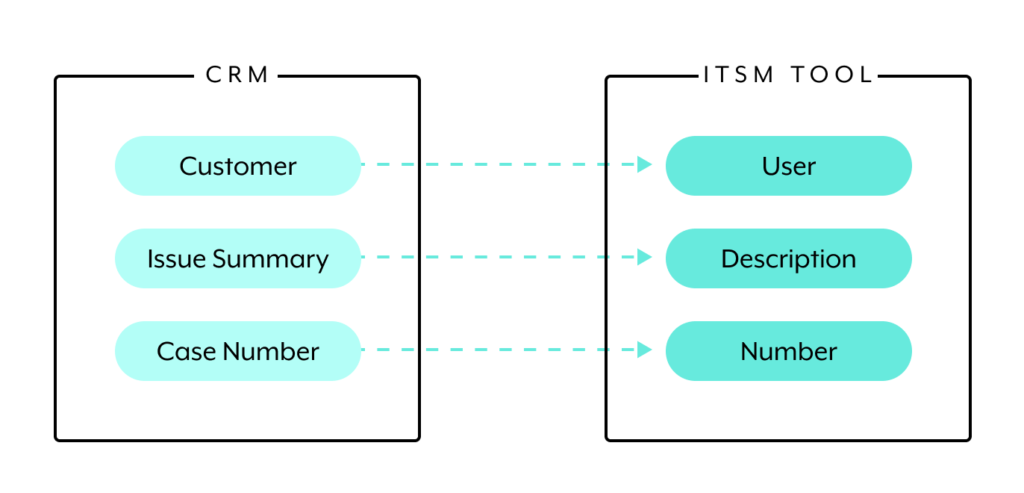
A one-way sync is simply when changes in the source system lead to changes in downstream systems, but not the other way around.
To help illustrate this definition, let’s use an example. Say you use a CRM as the source system and an ITSM tool as the downstream system, and you decide to synchronize the record types below. As a result, when a customer record, issue summary, or case number get modified in the CRM, the information in the corresponding ITSM records change accordingly. The inverse scenario—where changes occur in the ITSM tool’s records—however, doesn’t affect the CRM’s records.
Two-way data sync
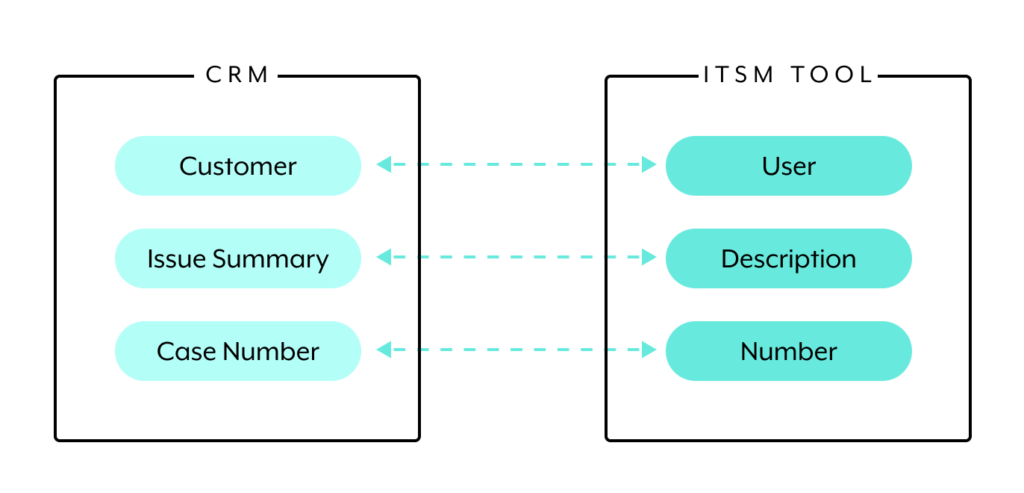
A two-way sync is when changes in either the source system or a downstream system lead to changes in the other systems.
Now, let’s use the same example from before but in the context of a two-way synchronization. In this scenario, it doesn’t matter which serves as the source and which serves as the downstream system. Whenever a synchronized record changes in either the CRM or ITSM tool, the corresponding record in the other system changes accordingly.
Finally, while it’s hard to generalize, the type of data that’s synchronized typically lives in a master data set. It’s also data that usually changes less frequently and that gets managed through a lifecycle.
With this data synchronization definition out of the way, let’s explore some common use cases.
Note: Information synchronization is often used interchangeably with data synchronization. For all intents and purposes, they share the same meaning.
Common data synchronizations
We’ll illustrate the points above by walking through a few real-word examples:
1. Syncing employee data
The process of adding a new hire into your systems typically starts by adding them into an HRIS; where information like the employee’s first and last name, email address, job title, and hiring manager get added.
Let’s say that a CRM is one of the downstream apps that needs employee information. You can build a one-way data sync where any time employee data changes in the data source (your HRIS), the corresponding changes take place in the CRM. Conversely, you can build a two-way data sync that behaves like the above AND allows for changes in your CRM to also lead to corresponding changes in your HRIS.
Related: What is integration middleware?
2. Syncing incident data
When two companies have a product that’s closely intertwined, they’ll likely want to track issues in their respective incident management platform; that way, the teams at each organization can keep tabs on any issue and, when appropriate, work to resolve any.
You can create a data sync that allows each company’s ITSM tool to be in line with the other. More specifically, you can build a two-way data sync where any time one company creates an incident in their tool, the other company’s tool also receives it. This allows the two teams to coordinate and work on resolving the issue faster.
3. Syncing customer data
Once a new client and their info gets added to your CRM, that data will likely need to be made available in a variety of other apps. These include customer success apps, reporting and analytics tools, marketing platforms, finance systems, etc.
Though it often depends on the company and situation, customer data is often better suited for a two-way sync. Why? Because a variety of functions that perform activities in apps outside of a CRM might uncover information or run into issues that require visibility from those that work in their CRM.
For example, an employee in finance might have trouble with invoicing a client. Using a two-way sync, they’d be able to create a case in their ERP system (highlighting the issue) and have the case also populate in the CRM. There, the sales rep can become aware of the invoicing issue and take action quickly.
Related: What is an ETL tool? And how is it different from an iPaaS?
Benefits of synchronizing data
Given these use cases, among countless others, it’s perhaps little surprise that synchronized data brings a wealth of benefits to the business.
Removal of data silos
Now that employees can access the data they need in the apps they work in, they can avoid the tedious process of requesting access to it—or worse, being unaware that the data even exists.
Prevention of extensive data entry
The process of inputting data manually isn’t just unpleasant for employees. It can also lead to human errors that impact data quality, whether that means employees input incorrect information or forget to input it at all. In response, employees are forced to perform a substantial amount of rework, which takes them away from other business-critical tasks.
Data synchronization ensures that employees don’t have to re-enter data across apps, and in doing so, it allows them to avoid the negative consequences highlighted above.
Several data operations can be performed
These include creating records, updating them, and deleting any.
By leveraging a combination of these operations across your apps, your data syncs can drive even greater value to your employees and the business.
Data can be synced in near real-time
While syncing data in batches might suffice for certain situations, near real-time synchronization is often invaluable for executing business processes successfully.
Real-time data synchronization allows sales and finance teams to collaborate more effectively in managing deals, it empowers product and customer support to resolve issues faster, etc.
Related: What is reverse ETL?
Data synchronization challenges
Common challenges of data synchronization include scalability issues, security risks, and performance limitations.
Let’s take a closer look at each issue:
Scalability issues
As we’ll cover further in the following section, many of the approaches for implementing and maintaining data syncs are resource-intensive. Your developers must get involved and invest a significant amount of time, which takes their focus away from core product initiatives.
Since your organization likely needs to implement and maintain dozens, and, eventually, hundreds of data syncs, this may prove difficult, if not impossible.
Security risks
The applications you’re connecting and the data synchronization flows you build likely have sensitive, business-critical information.
If the third-party or in-house solution you use to connect these systems and implement these syncs lacks proper security and governance controls, unauthorized parties can access sensitive data and use it in ways that compromise your business.
Data integrity issues
A critical challenge of data integration is data integrity maintenance. When you are transferring data between applications, incomplete updates, duplicate records, or format mismatches can result in inconsistencies. These issues can lead to conflicting or outdated information, thereby impacting trust in the data.
In absence of proper monitoring and data validation, with time, more errors can accumulate. This will impact operational efficiency and business decisions. Organizations need to ensure that they are implementing a robust error-handling mechanism to preserve data accuracy and reliability.
Performance limitations
While data synchronizations are, clearly, valuable, they only streamline the process of sharing information between applications. They also don’t provide the prescriptive guidance your employees need to take action off of the data.
For example, if you’re syncing cases in your CRM with incidents in your ITSM tool, your support team (using the latter) might not know how to immediately respond to these issues. And even if they do, their responses might require them to take additional steps that are manually intensive, which prevents them from providing a speedy resolution.
How to synchronize data
Once you’ve bought into synchronizing your data, you’ll need to think through the different solutions that can help you implement any sync.
Here’s a breakdown of each solution:
1. Custom coding
This approach relies on your developers using custom code to sync data.
This method is helpful in that it allows you to avoid working with and relying on third parties. However, your engineers must spend a significant amount of time implementing and maintaining these data syncs, which pulls them away from business-critical work that only they can perform..
2. Native integrations
This involves using an application’s pre-built integration and data flow with another application.
This can be cost-effective, as the app vendor that provides the integration may offer it at a low price point or even include it within your subscription. Also, depending on the data sync you’re looking to build, it may meet your requirements.
That said, there’s a good chance the vendor doesn’t offer out-of-the-box connectivity with all of the applications you’re looking to connect. And even if they do, these integrations may not connect to the endpoints you need.

3. Robotic process automation (RPA) software
RPA software lets you sync data by, essentially, using software scripts, or “bots”, to copy and paste data between applications on the UI level.
This can meet your requirements in the short run, but it’s likely to present issues over time. For example, something as simple as changing the name of a particular field or object can be enough to break the integration. Even moving a field or object to a different location within the UI can cause the data sync to break. In addition, the “bots” require technical expertise to implement and maintain. Similar to custom coding, this makes RPA software difficult to scale.
4. Integration platform as a service (iPaaS)
An iPaaS can help you implement data syncs by integrating applications at the API-level. This provides greater stability than UI-based integration, as changes to one of the application’s UIs won’t cause the data sync to break. Moreover, an iPaaS offers high performance, as APIs allow you to implement data syncs that work in, or near, real-time.
An iPaaS solution also typically provides a wide range of application connectors and automation templates. These can help your team implement integrations quickly and without having to involve developers.
It’s worth noting that iPaaS vendors can vary greatly across dimensions like ease of use, the use cases they address, and the quality of support they provide, which means you’ll need to evaluate your options carefully.
Ensuring reliable data synchronization in distributed systems
In distributed systems, we need data synchronization to maintain consistency across multiple databases, nodes, and applications.
We can achieve this through:
- Timely batch processing to update data at scheduled intervals.
- Event-driven updates where any change triggers immediate data synchronization.
- Peer-to-peer replication, where each node shares updates directly among themselves.
- Paxos, Raft, or similar consensus protocols that can maintain consistency across distributed environments.
Best practices for data synchronization in distributed systems
For effective data synchronization, we need to follow a few best practices:
- Making the system scalable by designing mechanisms for synchronization that adapt as the system grows.
- Monitor the synchronization for early discrepancy detection and resolution.
- Implement real-time synchronization to reduce delays and prevent outdated data.
- Implement multi-version concurrency control (MVCC) or last-write-wins and similar conflict resolution strategies.
Challenges of data synchronization in distributed systems and resolution
- Scalability issues: With an increasing count of synchronized nodes, the system becomes complex. Scalability can be enhanced with sharding and distributed databases.
- Network latency: Inconsistencies can be the result of delays in data transmission. Edge computing and distributed caching can help reduce this.
- Concurrency conflicts: When multiple nodes are updated simultaneously, changes may get overwritten. Implementing conflict resolution protocols and version control can prevent this.
- Risk of data integrity: System failures or incomplete updates can lead to data corruption or data loss. Implementing automated rollback mechanisms and robust error handling can prevent this.
Addressing challenges with effective solutions ensures reliable data synchronization. Following best practices further enhances consistency across distributed systems. This approach maintains seamless data flow and prevents discrepancies.
Use Workato to sync data at scale
Businesses now rely on multiple applications to manage complex operations. Ensuring seamless data synchronization is a necessity, not a luxury. Without a structured strategy, organizations risk data silos and security vulnerabilities. Inefficiencies and poor decision-making also become major concerns.
By implementing robust data sync practices, organizations can enable teams to access accurate, real-time data across systems. As a result, departmental collaboration improves, reducing manual data entry and enhancing decision-making capacities.
However, traditional approaches to data synchronization, like RPA or custom coding often require a lot of developer involvement and maintenance, making scalability a challenge.
This is where Workato comes in.
Workato, the leader in enterprise automation, offers a low-code/no-code platform that allows your team to implement data syncs without the use of developer resources, giving them the bandwidth to focus on other critical areas.
The platform supports both near-real-time and real-time data syncs. It uses triggers based on polling or webhooks. This ensures your system faces minimal latency and stays updated. Workato’s powerful automation eliminates the challenges of manual data sync. As a result, your business increases operational efficiency and drives growth.
Schedule a demo today to see how Workato can transform the way your organization manages data synchronization at scale.
Implement data syncs with ease by using Workato
Workato, the leader in enterprise automation, lets you implement data syncs without having to write a single line of code.