Distributed transactions fail partway through. Payment succeeds, then Salesforce times out. The guest is charged, but three systems hold stale state.
In production, this happens constantly: a system times out, a connection drops mid-request, a user submits unexpected input. In distributed systems, these failures often mean a transaction completes in one system and fails in another—requiring reconciliation to restore consistency across all systems.
What does this look like in composed MCP tools? When an LLM orchestrates multi-step workflows—potentially retrying, potentially calling the same tool multiple times—each tool represents a surface area for partial failure. Who enforces state reconciliation? How does that fit with the separation of concerns we’ve discussed in previous posts?
Idempotency handles retries. Error handling catches failures. Neither addresses partial success—when some operations complete before the failure point. Recovery requires knowing what succeeded and how to reverse it.
Previous posts covered composable skill design and serverless execution—how to structure tools and run them reliably. This post covers what happens when reliable execution still produces inconsistent state.
The Reference Architecture: Dewy Resort
Throughout this series, we use Dewy Resort—a hotel management system—as our reference implementation. The architecture spans multiple systems:
- Salesforce: Guest records, bookings, room inventory, sales opportunities
- Stripe: Payment processing, refunds
- MCP Tools: Orchestration layer connecting these systems via composed workflows
A single guest action like “check out” triggers operations across both systems: charge payment in Stripe, update booking status in Salesforce, mark room for cleaning, close the sales opportunity. Each system commits on its own timeline. The orchestrator sequences operations but can’t provide atomic rollback across system boundaries.
The complete implementation is open source.
The Problem: Consistency Without Transactions
Enterprise workflows need ACID-like guarantees—either everything succeeds or everything rolls back. But there’s no shared transaction boundary spanning systems. Stripe commits. Salesforce commits. Each has its own state, its own failure modes.
What This Looks Like: Multi-Object State
In Dewy Resort, a single checkout action updates three related Salesforce objects:
Booking__c
├─> Hotel_Room__c (lookup)
└─> Opportunity (lookup)
State dependencies:
- Booking.Status = "Checked Out"
→ Room.Status__c = "Cleaning"
→ Opportunity.StageName = "Closed Won"
When Booking transitions to “Checked Out,” Room and Opportunity must also transition. If any update fails, all three objects may be in inconsistent states—plus the Stripe charge has already succeeded.

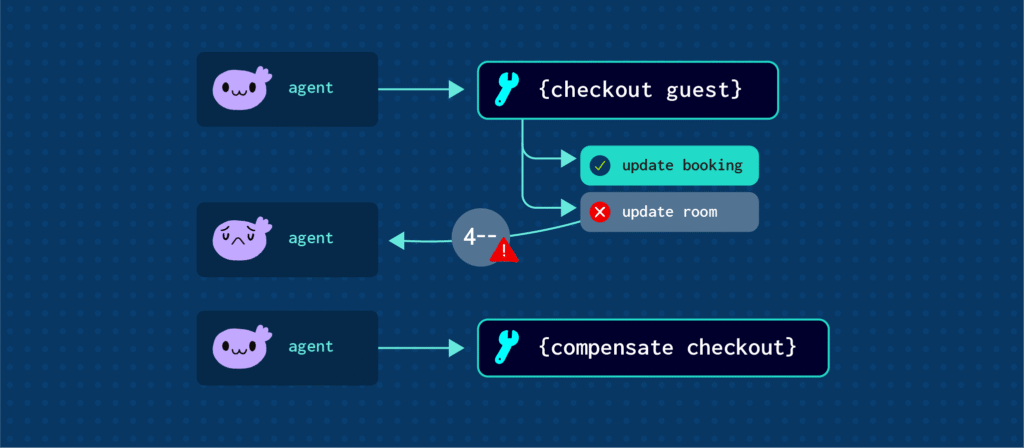
A Checkout Failure in Practice
Workflow: process_guest_checkout
| Step | Operation | Result |
|---|---|---|
| 1 | Search guest in Salesforce | ✓ |
| 2 | Create Stripe customer | ✓ |
| 3 | Create payment intent | ✓ |
| 4 | Confirm payment | ✓ ($250 charged) |
| 5 | Update Salesforce booking | ✗ Timeout |
| 6 | Update room status | — Skipped |
| 7 | Update opportunity | — Skipped |
Result: HTTP 500 returned to caller.
Actual state across systems:
| System | Actual | Expected | Match |
|---|---|---|---|
| Stripe | $250 charged | $250 charged | ✓ |
| Booking | Checked In | Checked Out | ✗ |
| Room | Occupied | Cleaning | ✗ |
| Opportunity | Negotiation | Closed Won | ✗ |
Guest paid, checkout incomplete. Room can’t be reassigned. Sales report wrong. Manual reconciliation: 30+ minutes.

Without a transaction boundary spanning systems, you have to build consistency yourself.
Why Try/Catch Isn’t Enough
A catch block logs the error and returns 500. It can’t distinguish between:
- Failed before payment → safe to retry
- Failed after payment → need refund or idempotent retry
- Failed during Salesforce update → need reconciliation to determine state
Traditional error handling is binary: success or failure. Distributed workflows have partial success. Recovery requires knowing what succeeded and how to reverse it.
A Perspective: Decision Placement
This series has argued for a clear separation of concerns between LLMs and backend systems. That principle applies directly to recovery logic: who should decide when to compensate, and who should execute the compensation?
This isn’t established industry practice—it’s a perspective we’re advocating based on our experience building MCP tools for enterprise contexts.
The Principle
These aren’t fully autonomous systems. They’re agents assisting humans—so the real question is where human judgment belongs versus where deterministic execution belongs.
Humans + LLMs decide WHEN to act and WHICH workflow.
Backend workflows decide HOW to act and WHAT state transitions.
Financial and security decisions always go to backend.
Human + LLM Decisions
Non-deterministic, context-dependent—where judgment matters:
- Understanding user intent (“I want to check out” → tool selection)
- Selecting the right workflow (checkout vs compensation)
- Extracting parameters from natural language
- Confirming actions with users before execution
- Explaining results to users
Backend-Appropriate Decisions
Deterministic, rule-based—where consistency matters:
- Payment status routing (succeeded/requires_action/failed)
- State validation (can this transition happen?)
- Business rule enforcement (check-in window, eligibility)
- ID resolution (email → Contact ID)
- Error categorization (retryable vs permanent)
Applied to Recovery: Who Decides to Compensate?
We built capacity for both paths:
- LLM-driven: Staff member receives guest complaint (“I got charged but checkout failed”). Staff-facing agent verifies the problem, calls compensation, explains outcome.
- Automated: Scheduled job queries for orphaned payments, triggers compensation automation based on business rules.
Same compensation tool, different trigger mechanisms. Conversational UX for reported issues; automation catches unreported failures.
On tool exposure: The compensation tool exists only on the staff MCP server—there’s no guest-facing version. Some tools simply don’t make sense for certain audiences. There’s no “refund on behalf of guest” capability because allowing guests to trigger unmediated refunds isn’t sound business logic. Tool exposure is itself a layer of authorization, complementing the approach to building authorization into tool design discussed earlier in this series.

Why This Matters
| Principle | Implementation | Rationale |
|---|---|---|
| Strategic vs tactical split | LLM selects workflow; backend executes it | Clear separation enables independent testing |
| Financial logic in backend | Refund amounts, payment routing, charge validation | Deterministic, auditable, not subject to prompt variation |
| Multiple trigger mechanisms | Same tool callable by LLM or cron job | Flexibility without duplicating logic |
Two Patterns for Recovery
Two established patterns address partial failure recovery directly. Both are implemented in Dewy Resort.
Pattern 1: Compensating Transactions (Saga Pattern)
The saga pattern treats multi-step workflows as a sequence of operations, each with a corresponding compensating transaction that reverses its effect.[1]
Use this pattern when:
- Multi-system workflows can partially succeed
- Financial operations are involved
- State consistency affects user experience
- Manual reconciliation cost exceeds automation cost


How It Works
When checkout fails after payment succeeds, the compensation tool:
- Validates payment state (is it refundable?)
- Issues refund (financial operations first)
- Checks Salesforce state and reverts if needed
The tool accepts what callers naturally have:
{
"tool": "compensate_checkout_failure",
"parameters": {
"payment_intent_id": "pi_3ABC...",
"guest_email": "beth.gibbs@email.com",
"idempotency_token": "comp-pi_3ABC...",
"reason": "Salesforce timeout during checkout"
}
}
Design Principles
| Principle | Implementation | Rationale |
|---|---|---|
| Check state before reversing | Query current state, only update if needed | Makes compensation idempotent—safe to retry |
| Financial operations first | Issue refund before Salesforce cleanup | Guest harm reversed immediately; data fixable async |
| Business identifiers in, system IDs hidden | Accept guest_email, resolve to Contact ID internally | LLM has email from conversation; logs stay readable |
| Idempotency at every layer | Client token → Backend check → Stripe Idempotency-Key | Safe to automate; no double-refunds |
Pattern 2: Fail-Fast Validation
Validate assumptions before expensive operations. Preventing failures is cheaper than compensating for them.
Use this pattern when:
- Operations have prerequisites that could be violated
- Downstream operations are non-idempotent (payments, external API calls)
- Clear error messages can guide callers to fix input
Example: The Multiple-Bookings Bug
Original code assumed one booking per guest:
search_booking(guest_email)
update_booking(bookings[0].id, status: "Checked Out")
Problem: What if bookings has 0 or 2+ elements?
length == 0: Accesses undefined → crashlength > 1: Updates first booking (might be wrong one)
The fix—explicit validation before array access:
bookings = search_booking(guest_email)
IF bookings.length == 0:
→ Return 404 "No checked-in booking found for this guest today"
IF bookings.length > 1:
→ Return 400 "Multiple bookings found. Provide room_number or booking_number to disambiguate"
IF bookings.length == 1:
→ Proceed with checkout
This stops execution before charging payment. If validation happened after payment, you’d need compensation.

Design Principles
| Principle | Implementation | Rationale |
|---|---|---|
| Validate before non-idempotent operations | Check prerequisites before payments, external calls | Failures prevented > failures compensated |
| Validate array lengths | Check length before accessing elements | Prevents crashes and wrong-record updates |
| Return actionable errors | Specific codes (400/404/409) with guidance | Callers can fix input without guessing |
Recovery Strategy Quick Reference
| Strategy | When to Use | Example |
|---|---|---|
| Compensating transaction | Financial operations, state consistency critical | Payment succeeded, Salesforce failed → Issue refund |
| Acceptable orphan | Resource has low/zero cost, will be reused | Stripe customer created, checkout failed → Customer reused on retry |
| Fail-fast validation | Preventing failure cheaper than recovering | Multiple bookings found → Return 400 before payment |
| Retry with idempotency | Transient failure, operation is idempotent | Salesforce timeout → Retry with same token |
Is Your Tool Recovery-Ready?
Saga Pattern
- Compensation orchestrator exists for financial operations
- Compensation checks state before reversing (idempotent)
- Financial compensation prioritized over data cleanup
- All compensation actions logged for audit trail
- Idempotency tokens flow through entire compensation flow
Fail-Fast Validation
- Array lengths validated before element access
- Prerequisites checked before non-idempotent operations
- Error codes are specific with actionable guidance
Decision Placement
- Strategic decisions (when, which workflow) → LLM
- Tactical decisions (how, what transitions) → Backend
- Financial/security decisions → Backend (always)
- Multiple trigger mechanisms supported where needed
Conclusion
MCP standardizes how LLMs discover and invoke tools. What those tools do—and how they handle partial failures, state consistency, and recovery—is architecture you build into the tools themselves.
The saga pattern provides compensating transactions when multi-system workflows fail partway through. Fail-fast validation prevents failures by checking assumptions before expensive operations. Decision placement—where recovery logic lives—determines whether your system is testable, auditable, and flexible.
You can see these approaches in the Dewy Resort sample application. We’ve built a checkout orchestration tool that handles Stripe and Salesforce coordination, financial operations, state consistency across Booking/Room/Opportunity, automatic compensation, and idempotency at every layer.
Implementation: The complete Dewy Resort Hotel example is open source: github.com/workato-devs/dewy-resort
This post builds on Designing Composable Skills for MCP Tools and Serverless MCP Execution. For more on composable architecture patterns, see the complete series.
- The saga pattern was introduced by Hector Garcia-Molina and Kenneth Salem in their 1987 paper “Sagas” ACM SIGMOD. For a modern treatment, see Chris Richardson’s Saga pattern documentation.