In the first two posts of this series, we explored why enterprise MCP needs compositional architecture and how to design skills that abstract complexity from the AI agent. But there’s a question we haven’t addressed: how do those tools actually execute at runtime?
The Model Context Protocol defines how AI agents discover and invoke tools. But the protocol says nothing about persistent connections vs. stateless HTTP, session-cached state vs. source-of-truth lookups, or long-running processes vs. queue-based workers. These runtime decisions determine whether your system scales, fails gracefully, and stays debuggable.
Most MCP implementations assume persistent connections and session state. This post explores a different approach: serverless MCP, where every tool call is an independent HTTP request, executed by any available worker in a distributed pool, with no state stored in the MCP server itself.
We’ll continue with our hotel operations system to show how we built this using Workato’s cloud-native iPaaS and enterprise MCP—and why stateless execution matters for production AI.
What Is Serverless MCP?
Serverless MCP isn’t about AWS Lambda or “no servers.” It’s a set of three specific architectural choices:
Connection model: HTTP request-response per tool call, not persistent WebSocket/SSE connections.
State management: No session state in the MCP server. The source of truth lives in your systems of record (CRM, databases, etc). The MCP layer is stateless.
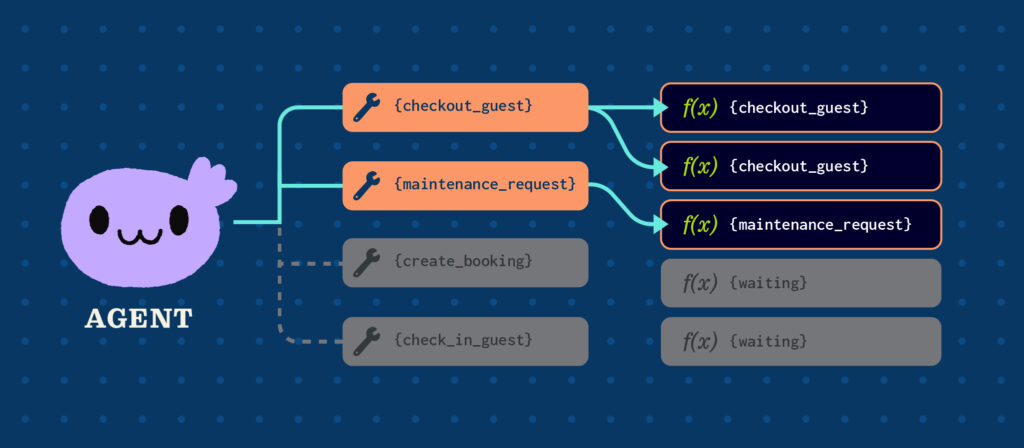
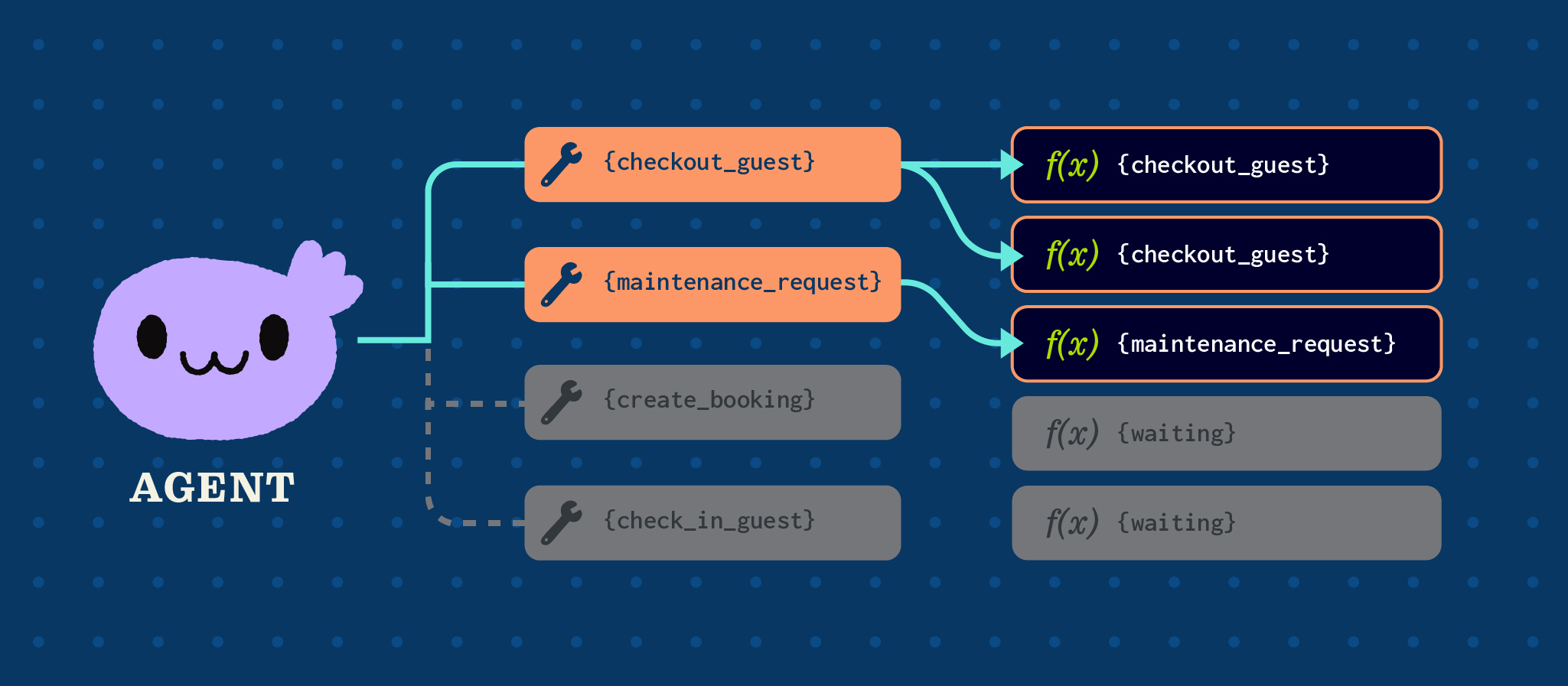
Execution model: Tool calls are queued immediately upon arrival. Any available worker pulls from the queue and executes. No server affinity—the worker that handles client requests might be different every time.
These choices have cascading effects across the entire system:
| Aspect | Traditional MCP | Serverless (managed) MCP |
|---|---|---|
| Connection | Persistent WebSocket/SSE | HTTP request per tool call |
| State | Session-based (cached in server) | Stateless (external systems = source of truth) |
| Scaling | Vertical, or complex load balancing | Horizontal (queue depth triggers auto-scaling) |
| Execution | Long-running server process | Queue-based workers, allocated just-in-time |
| Fault tolerance | Connection drops require reconnect | Queued events survive worker crashes |
| Idempotency | Must implement manually | Declarative control logic |
| Deployment | Custom server code, process management | Recipe descriptors, zero infrastructure ops |
An individual MCP client could be identical in both cases. The difference is entirely in how backend systems respond to those tool invocations.

When Does Server Choice Matter?
Serverless* MCP excels when:
You’re orchestrating across multiple (external) systems.
A hotel checkout touches Stripe (payment), Salesforce (booking status, room status, opportunity stage), and possibly Twilio (confirmation SMS). Each external API call takes at least 600-1200ms. The overhead of HTTP vs. WebSocket is insignificant noise (~50ms) compared to the overall 4-7 seconds spent waiting on external systems.
Your load is variable or unpredictable.
Traffic spikes during batch processing, end-of-day reconciliation, or pilot rollouts. Queue-based execution scales automatically. Worker pools grow when queue depth increases, shrink when it decreases. No capacity planning required.
Your team is operations-constrained.
Small teams without dedicated DevOps still need enterprise-grade reliability. Managed serverless MCP offerings (like Workato’s enterprise MCP) offload infrastructure concerns (scaling, health checks, connection pools, OAuth token refresh) to the underlying operating platform. (DIY serverless MCP would NOT necessarily benefit these kinds of teams.)
You need audit trails and guaranteed delivery.
In a managed serverless MCP implementation, every tool call is persisted to a distributed queue before execution begins. If a worker crashes mid-execution, the event survives. Transaction-level logging comes free.
*Some of the benefits here are specific to what I’m calling a “managed serverless” (i.e. running on a platform-as-a-service substrate) implementation. These are noted in the text.
Traditional MCP makes sense when:
You need streaming responses.
HTTP request-response is all-or-nothing. If you need incremental results as data arrives—search results appearing one by one, progress updates during long operations, real-time transcription—you need WebSocket or SSE transports. This is an architectural constraint, not a performance trade-off.
You need server-initiated communication.
Stateless HTTP means the server only responds to requests; it can’t push. If your tools need to notify the client asynchronously (alerts, status changes, collaborative updates), you need persistent connections or a separate notification channel.
Connection overhead would dominate the workload.
HTTP setup adds ~50ms per request. For enterprise integrations hitting systems like Salesforce or Stripe (600-1200ms per API call), that’s trivial—acceptable friction that disappears into the overall latency. But if your tools perform fast (less than <50ms) internal operations like cache lookups, in-memory computations, microservice calls, that per-request overhead would become the dominant cost per execution. These costs typically add up more in internal service-to-service communication than SaaS connectivity use cases.
What NOT to put into an MCP Server (no matter the architecture)
As I’ve discussed before: MCP is a narrow protocol. Keep it that way. MCP defines tool interfaces. Your backends execute operations, manage state, and handle errors. If you find yourself thinking: “I need persistent connections to maintain state across tool calls,” you are putting that responsibility in the wrong layer.
Serverless MCP forces a certain amount of architectural discipline—you can’t store session state, so you design systems that don’t need it.
How Serverless Execution Works
Let’s look at how Workato’s cloud-native architecture implements serverless MCP.
Recipes as Descriptors, Not Deployed Applications
In traditional integration platforms, you deploy an application to a server. The app “belongs” to that server—tight coupling. On the Workato platform, a common developer artifact is a multi-step automated integration workflow, called a “recipe.” In Workato’s architecture, recipes are descriptors of intent, not deployed code.
From Workato’s Cloud-Native Architecture whitepaper:
“Recipes are descriptors of the ‘builder’s intent’ and are decoupled from our execution runtime. Recipe logic is evaluated on-demand during execution by any available (idle) server, thus removing the notion of a ‘deployed app’ and closely aligning with a serverless execution paradigm.”
This means:
- Any worker can execute any tool call (no server affinity)
- Platform upgrades don’t require redeploying recipes (zero downtime)
- Workers are allocated just-in-time, not pre-assigned
Queue-Based Execution Flow
When a tool call arrives:
- HTTP POST hits the API Platform
- Request is immediately persisted to a distributed queue
- Platform returns acknowledgment
- Any available worker pulls the event from the queue
- Worker evaluates the recipe descriptor, executes each step
- Response returned (or error handled)
If a worker crashes mid-execution, the event persists in the queue. Another worker picks it up. Guaranteed delivery without custom retry logic.
Where State Actually Lives
In our Dewy Resort implementation, state lives in exactly three places:
CRM/backend systems (source of truth): Guest contacts, hotel bookings, rooms, service cases, opportunities. Every tool call queries current state—no caching, no staleness.
Client-side idempotency tokens: UUIDs generated by the client, passed with every create/update operation. The backend checks for existing records with matching external IDs before creating new ones. Safe to retry.
Platform-managed connections: OAuth tokens and API keys stored in Workato’s encrypted vault. Automatic token refresh. Managed at the workspace level, not per-request.
What’s not stored in the MCP server: session state, conversation history, connection pools, cached results. Nothing.
Real Example: Guest Check-In
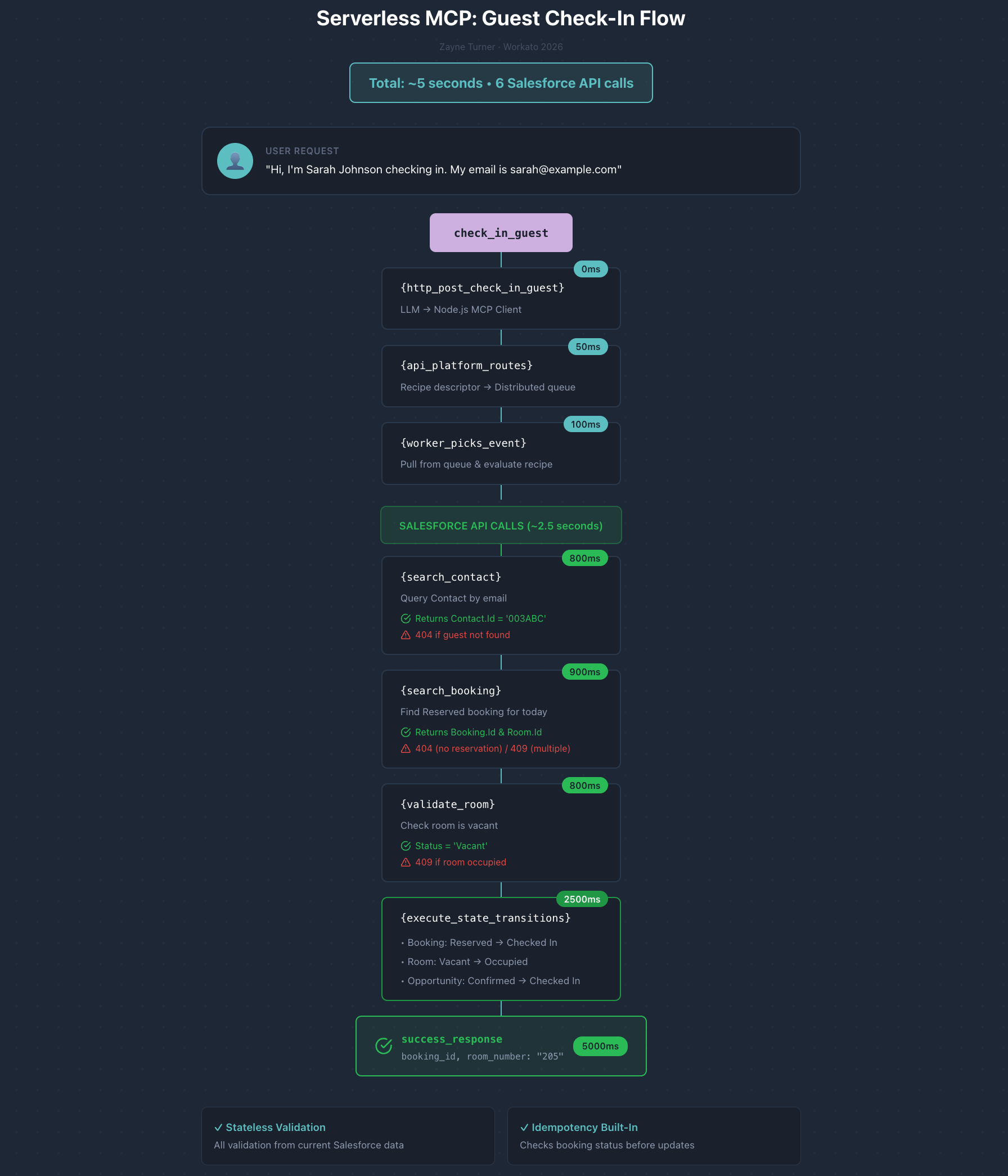
A guest says: “Hi, I’m Sarah Johnson checking in. My email is sarah@example.com.”
The LLM calls the check_in_guest tool:
{
"tool": "check_in_guest",
"parameters": {
"guest_email": "sarah@example.com",
"idempotency_token": "a]550e8400-e29b-41d4..."
}
}Anatomy of the orchestrator recipe:
- Searches Salesforce for Contact by email (800ms)
- Searches for Booking with status=Reserved, date=today (900ms)
- Validates Room status is Vacant (800ms)
- Updates Booking status: Reserved → Checked In
- Updates Room status: Vacant → Occupied
- Updates Opportunity stage: Booking Confirmed → Checked In (~2500ms for all state changes)
Total: ~5.5 seconds. Five Salesforce API calls.
Any worker could have executed this—the one that did was simply the next idle worker in the pool.
Stateless validation: Every check queries current Salesforce data. No session state needed.
Idempotency built-in: If the booking is already “Checked In,” the operation returns success without duplicating work. Safe to retry on network failure.
Implementation Patterns
Four patterns that make serverless MCP work in production:
1. Compositional Tool Design
Don’t expose raw APIs as MCP tools. Design tools around user intent.
Naive approach (11+ tool calls for a checkout):
get_guest_by_email, get_booking_by_guest, get_room_by_booking,
create_payment_intent, charge_payment_method, send_receipt_email,
update_booking_status, update_room_status...Compositional approach (2 tools):
check_in_guest (orchestrator)
checkout_guest (orchestrator)Each orchestrator composes multiple atomic operations internally. The complexity moves to the backend, where it’s governed, tested, and observable.
Why this matters for serverless: fewer round trips (lower latency), atomic operations (easier retry logic), encapsulated business rules (consistent validation).
2. Idempotency at Every Layer
Every tool that creates or modifies data accepts an idempotency token:
{
"idempotency_token": "550e8400-e29b-41d4-a716-446655440000",
"guest_email": "sarah@example.com",
"amount": 15000
}The backend checks for existing records before creating:
IF Case.External_ID__c = idempotency_token
→ Return existing case (already created)
ELSE
→ Create new case with External_ID__c = idempotency_tokenExternal APIs enforce their own idempotency (Stripe’s Idempotency-Key header deduplicates within 24 hours).
Result: network retries are always safe. No duplicate bookings, no duplicate charges.
3. Business Identifiers Over System IDs
Tightly coupled (exposes your database schema):
{
"contact_id": "003Dn00000QX9fKIAT",
"booking_id": "a0G8d000002kQoFEAU"
}Human-readable (lets the backend resolve IDs):
{
"guest_email": "sarah@example.com",
"room_number": "205"
}The recipe resolves emails and room numbers to Salesforce IDs internally. The LLM doesn’t need to know your data model. Logs become human-readable. Each request is self-contained.
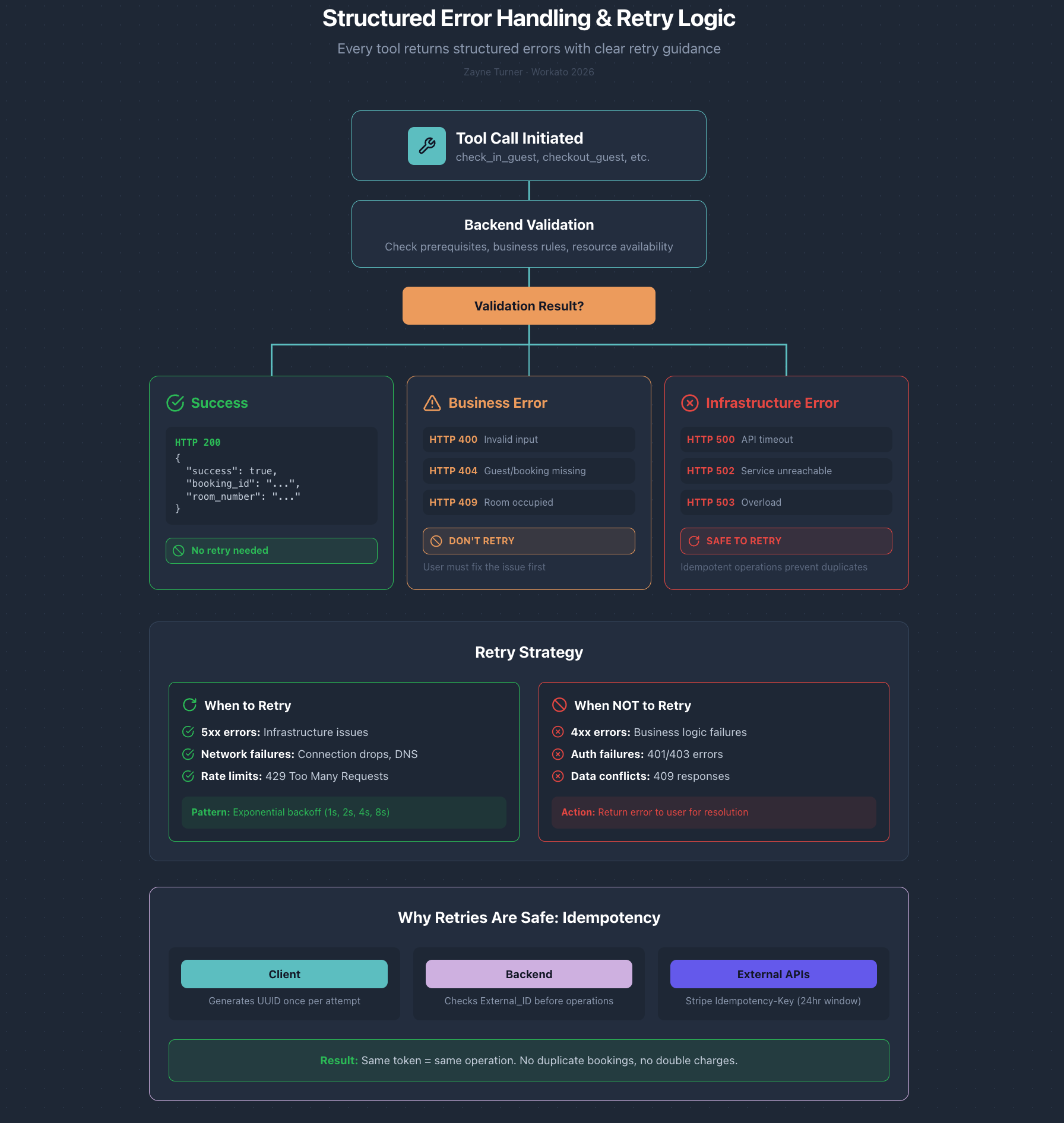
4. Structured Error Contracts
Every tool returns structured responses:
type ToolResult =
| { success: true; data: ResultData }
| { success: false; error_code: string; error_message: string; retry_safe: boolean };Error codes map to HTTP status:
- 200: Success
- 400: Validation error (bad input)—don’t retry
- 404: Resource not found—don’t retry
- 409: Conflict (room unavailable, multiple reservations)—don’t retry
- 500: Infrastructure error—safe to retry
Performance Reality
The bottleneck in serverless MCP is external APIs, not the execution model. Let’s walk through some of the benchmarks from our application testing and tool executions.
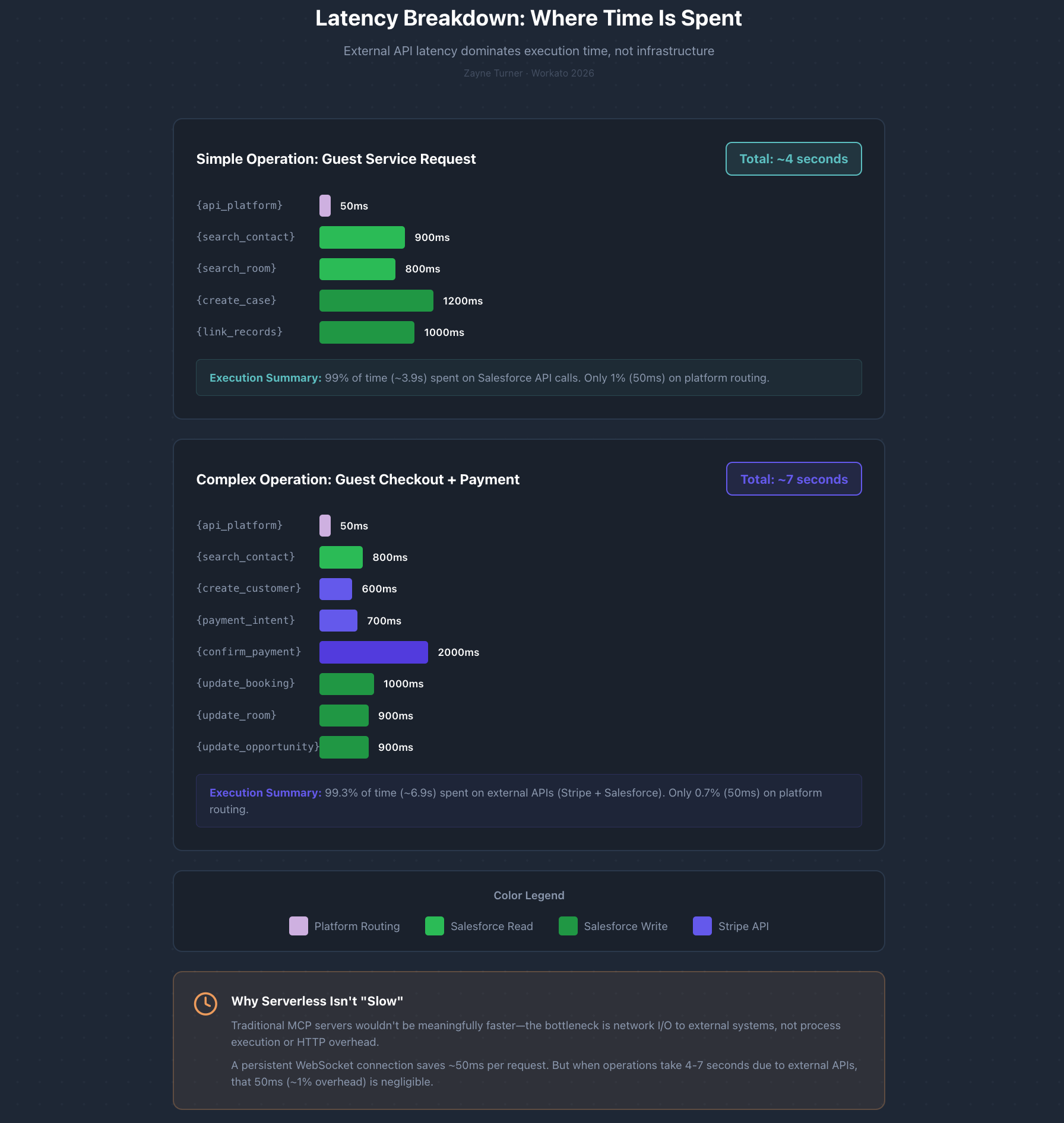
Latency Breakdown
Typical check-in (~5.5 seconds total):
- API Platform routing: 50ms
- Search Contact: 800ms
- Search Booking: 900ms
- Update Booking: 800ms
- Update Room: 800ms
- Update Opportunity: 900ms
Complex checkout with payment (~6.8 seconds total):
- API Platform routing: 50ms
- Search Contact: 800ms
- Create Stripe Customer: 600ms
- Create PaymentIntent: 700ms
- Confirm Payment: 2000ms (includes bank authorization)
- Update Booking: 1000ms
- Update Room: 900ms
- Update Opportunity: 900ms
98%+ of execution time is spent waiting on systems like Salesforce and Stripe. A persistent-connection MCP server wouldn’t be meaningfully faster—the latency is in the business process, not the protocol.
Throughput Benchmarks
Workato API Platform: 100 requests/second per workspace, auto-scaling worker pools, distributed queue prevents backpressure.
Our test results: 20 concurrent tool calls from multiple LLM instances, no contention or throttling, linear scaling observed.
Practical bottleneck (for our fictional app): Salesforce dev sandbox allows 15,000 API calls per 24 hours. A typical checkout workflow uses 8-9 Salesforce calls. That’s ~1,500 checkouts per day—limited by Salesforce, not Workato.
Lessons Learned
What worked
Idempotency everywhere. Client-generated UUIDs + external ID fields in Salesforce made retries trivial. Zero duplicate bookings or charges from test cases through final deployments.
Compositional design. When checkout_guest failed, we could test create_stripe_customer in isolation. Breaking workflows into orchestrators + atomic operations made debugging dramatically easier.
Business identifiers. Troubleshooting meant grepping for “sarah@example.com” instead of decoding “003Dn00000QX9fKIAT”. Human-readable logs matter.
Structured errors. Consistent error codes (GUEST_NOT_FOUND, ROOM_NOT_VACANT) let us document recovery paths. The LLM could guide users appropriately based on error type.
What we’d do differently
Treat your test datasets like artifacts. We generated synthetic test data during design, but didn’t consistently backport changes as we iterated on the real app. The mocks drifted—reflecting original assumptions, not actual behavior. This debt compounded at the orchestration layer: we burned significant time recreating complex payloads that accurate atomic datasets would have provided for free. Generate mocks early, and maintain them like production code.
Keep atomic operations truly atomic. We started with compositional design as our intent, but still managed to sneak transactional behavior into orchestrators and mix independent read/write transactions into the same “atomic” recipe. Splitting out functionality like search_contact_by_email from an orchestration into its own recipe not only improved reuse–it significantly improved debugging.
Make tool descriptions explicit. The LLM struggled with ambiguous names. “Check in guest” vs. “Check in guest (requires existing reservation)” made a real difference. There is more guidance about this in my previous post, focused on putting composable tool design into practice (link below).
Production-friendly benefits
Zero downtime for recipe changes. Update validation logic, redeploy—workers pick up the new version automatically. No restarts, no reconnects.
Painless scaling. Tested concurrent requests without thinking about it. Workers auto-scaled. No connection pool tuning.
Audit trail for free. Transaction-level logging saved us during a Salesforce API outage. We could see exactly which operations completed vs. failed, replay failed requests once service restored.
Conclusion
As AI agents move into production, your MCP server architecture matters more than the protocol itself.
Traditional MCP—persistent connections, session state, server affinity—works for experiments. Production systems need:
- Horizontal scalability without manual tuning
- Guaranteed delivery with built-in retry safety
- Transaction-level observability for debugging and compliance
- Idempotency by design, not as an afterthought
Serverless MCP delivers this by making statelessness a constraint, not an option. You can’t store session state, so you design systems that don’t need it. You can’t rely on server affinity, so you build idempotent operations. The architecture forces good discipline.
The protocol won’t save you from bad architecture. But stateless execution—queue-based workers, external systems as source of truth, idempotency at every layer—transforms MCP from a technical curiosity into a production-grade integration layer.
Resources
- Dewy Resort Hotel (Open Source): github.com/workato-devs/dewy-resort
- Workato Cloud-Native Architecture: Architecture Deep Dive Whitepaper
- Model Context Protocol Spec: modelcontextprotocol.io
- Previous post: Designing Composable Tools for MCP