

In recent weeks we’ve published guides on validating input into your data pipelines, and on wrangling semi-structured data into a useful form. But what if we’re dealing with completely unstructured data? Examples of unstructured data could include:
- Raw text of emails to your support inbox
- Recordings or transcripts of sales calls
- Social media posts that mention your brand
- Digital images of documents, like invoices
This sort of data can be immensely valuable, but in its raw form, it can’t be used to drive automations. To be successful, we need to extract some form of structured, actionable information from the raw data. This may require several steps depending on the original format. For example, we might first need to convert image or audio data to text, using optical character recognition (OCR) or speech recognition. From there we can use natural language processing (NLP) to extract intent, sentiment or keywords from the text.
The details of the solutions you will need to extract meaning from unstructured data will be unique to your specific use case. But to give you some inspiration for how you can use Workato to bring order from chaos, let’s work through a simplified example. We’ll build a recipe to create Zendesk support tickets from raw emails, using some publicly available NLP tools.
How to do it
Obtain credentials
For this example, we’ll use two publicly available NLP services that include free tiers. We’ll need to create an account and API credentials for each:
- IBM Watson Tone Analyzer for sentiment analysis
- MonkeyLearn for keyword analysis
To send data to these two services, we’ll use Workato’s HTTP Connector, which uses a simple wizard interface to connect to any HTTP API endpoint.
Define input
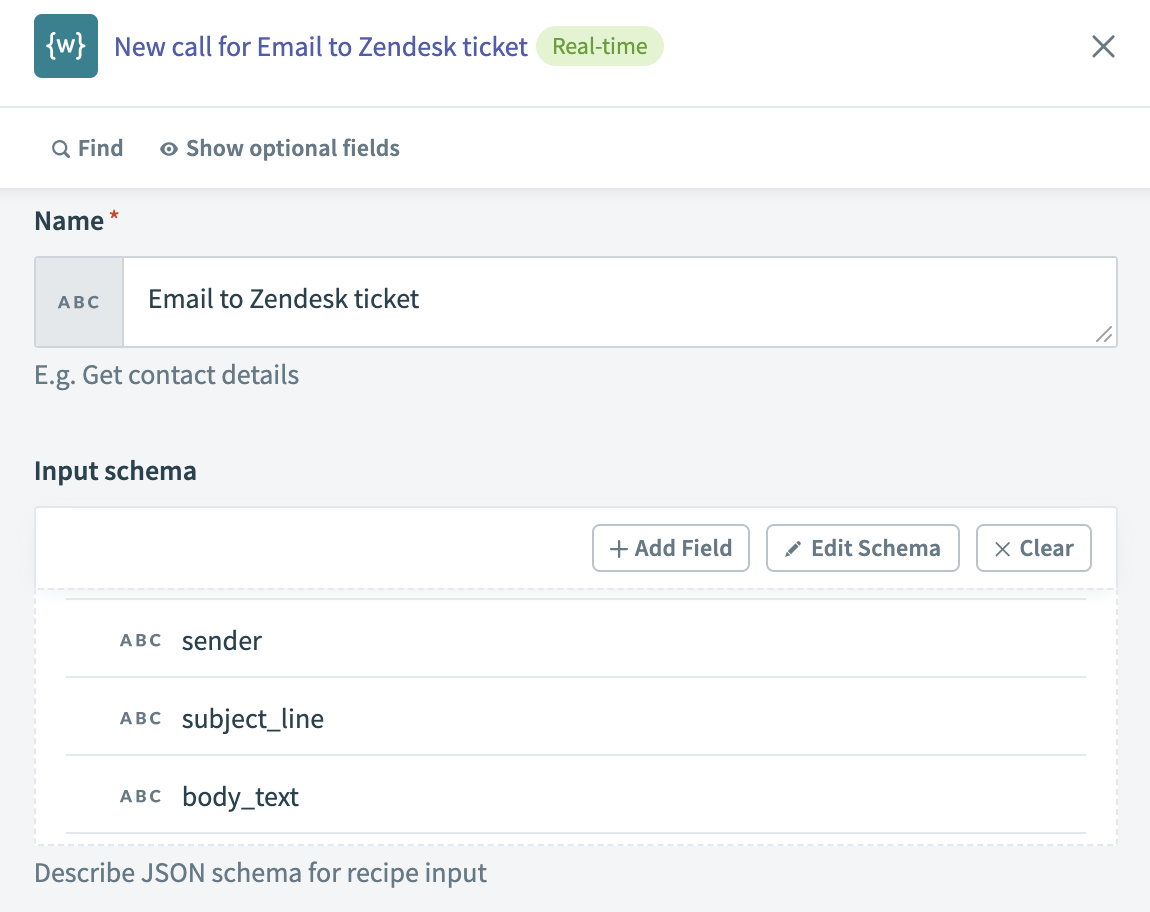
We’ll set up our unstructured data processor as a callable recipe in Workato. To use the recipe to process an email, we’ll need the sender’s email address, the subject line, and the raw text body.
Pre-process raw data
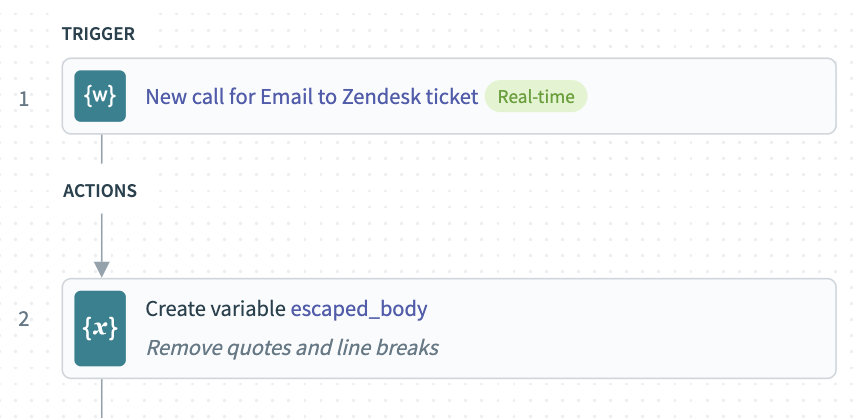
It’s possible that you may need to perform some basic transformations on your raw data in order to make it usable. For example, in this case we’ll be sending the raw email text to our NLP services in JSON format, so we need to either escape or strip any quotation marks or line breaks.

Sentiment Analysis
We’re ready to send the escaped text body of the email to our NLP services. IBM Watson Tone Analyzer accepts a body of text and attempts to determine the presence of “tones” or sentiment. Possible tones include “anger”, “fear”, “joy”, and “sadness”. Since we’re processing emails to customer support, we’re particularly interested in anger. To extract a usable sentiment data from our email:
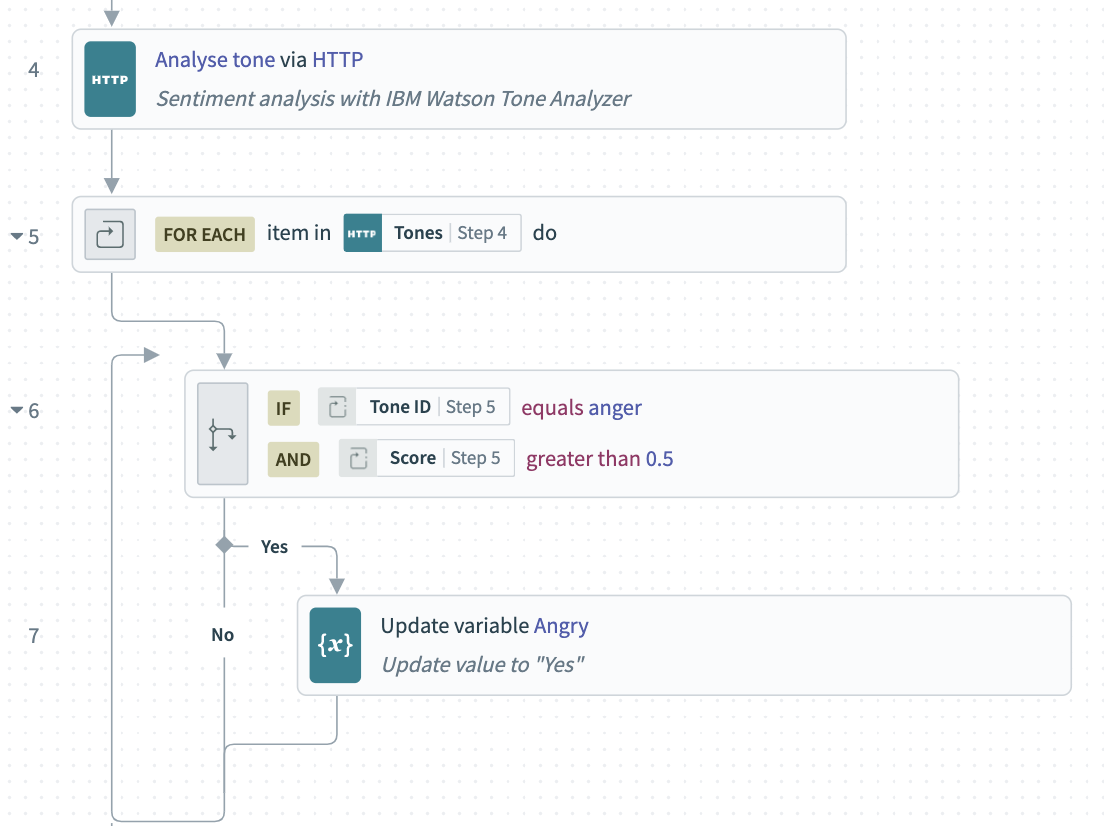
- Create an
Angryvariable that defaults toNo. This variable will eventually help to determine the priority we set on the Zendesk ticket. - Use Workato’s HTTP Connector, and the credentials we created, to send the escaped body of the email to IBM Watson Tone Analyzer. We’ll get back an array of tones the service found in the message.
- If any of the included tones is
"anger", and the confidence score is0.5or higher, we’ll update the value ofAngrytoYes
Keyword Analysis
Next we’ll create a similar pattern that uses MonkeyLearn to extract keywords from the email text. For example, if we get an email from a user that is unable to login, we might extract keywords like “login”, or “password reset”. These keywords can be added as tags to the support ticket and used for routing or analytics. To extract keyword data:
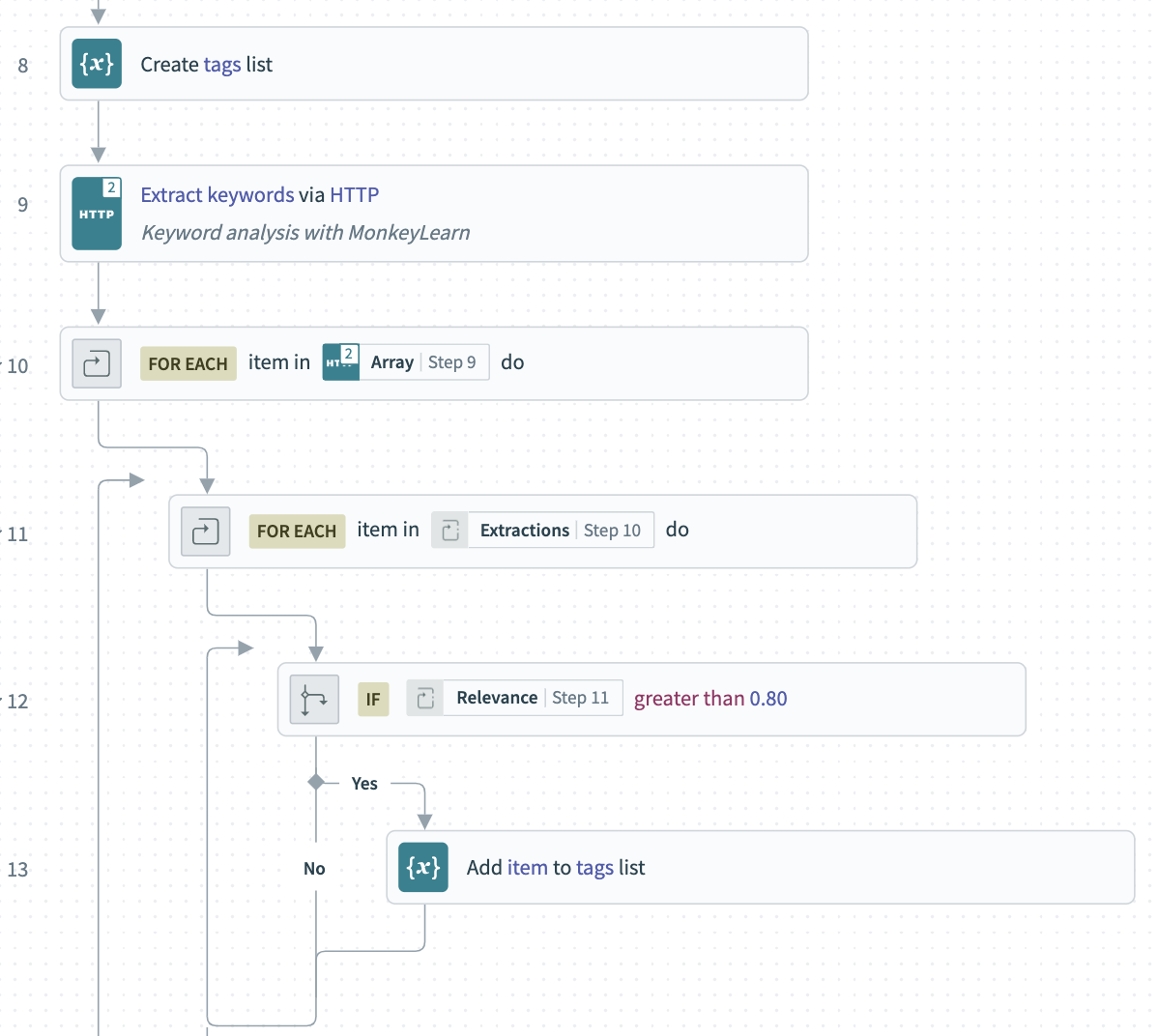
- Create a list of
tags - Using the HTTP connector and the credentials we created for MonkeyLearn, send the escaped body of the email to the Keyword Analyzer
- For each extracted keyword, check the relevance score. If greater than
0.8, add it to thetagslist.
We may need to tweak our relevance criteria after testing. If we get keywords that don’t seem relevant to the text of the email, we can raise the required score. If we’re not getting enough keywords, we can lower it.
Create the ticket
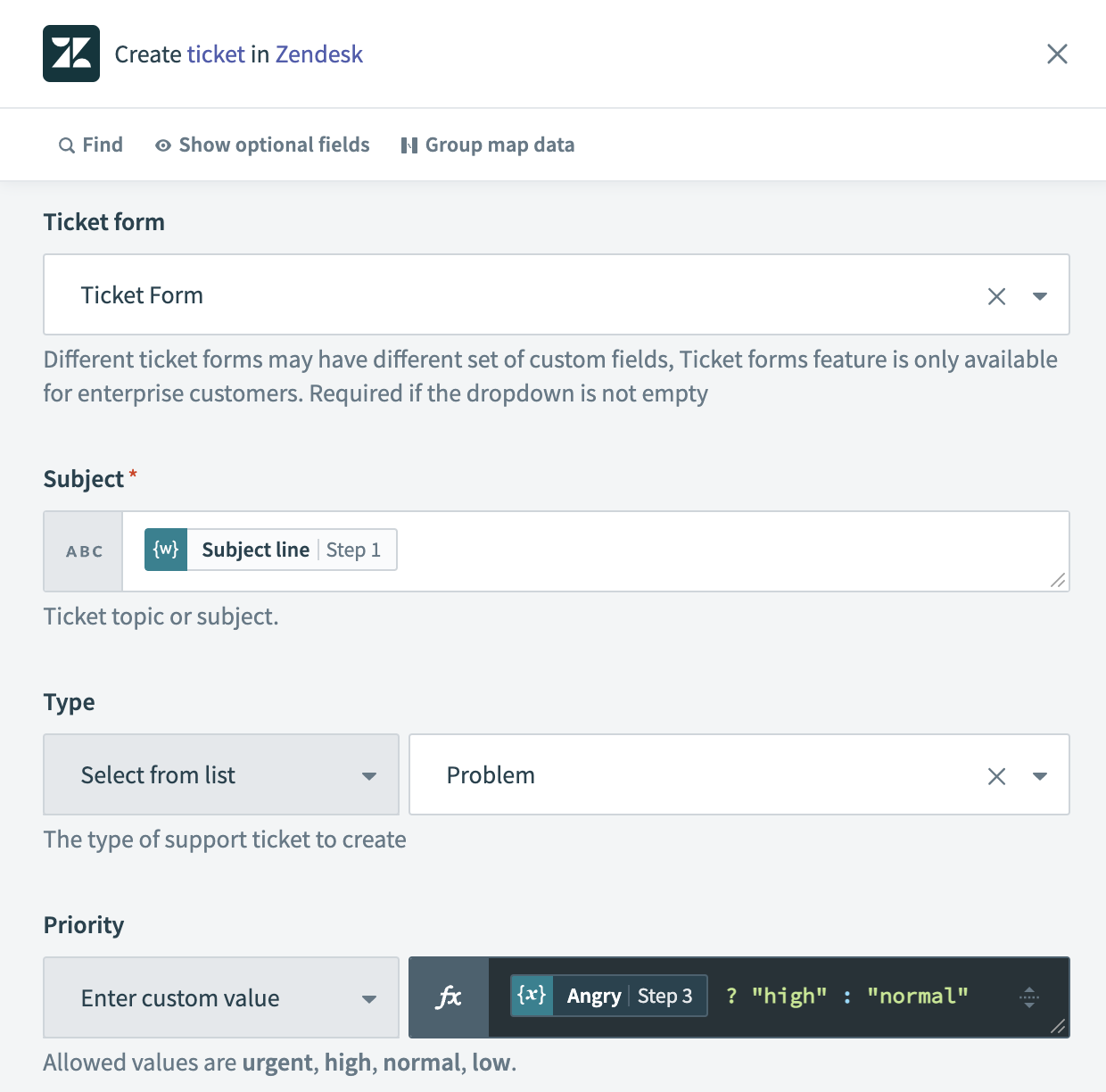
To put it all together, we’ll use the Zendesk connector to create a new ticket, setting the following values:
- Subject: the subject line of the email
- Priority: using a conditional formula, set to
"high"if ourAngryvariable is set toYesand"normal"if not. - Tags: Zendesk takes tags as a single string separated by commas, so we just need to use the
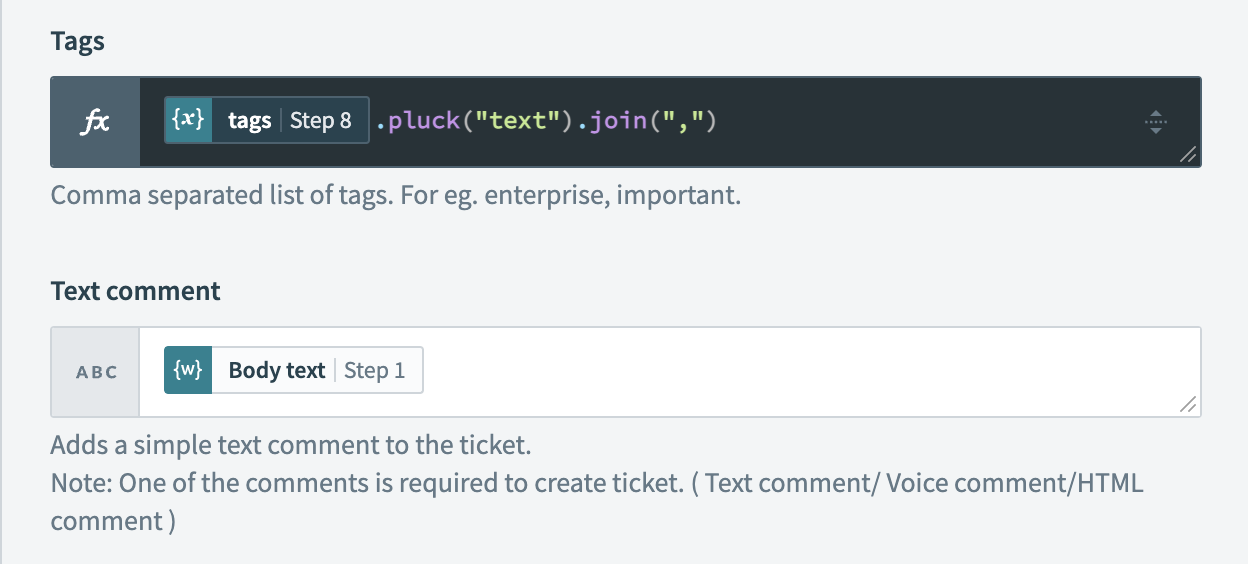
joinformula to turn our list of tags into a string.
- Text comment: the original body of the email
Result
We can now try out our recipe with a test email, and check the resulting ticket in Zendesk.
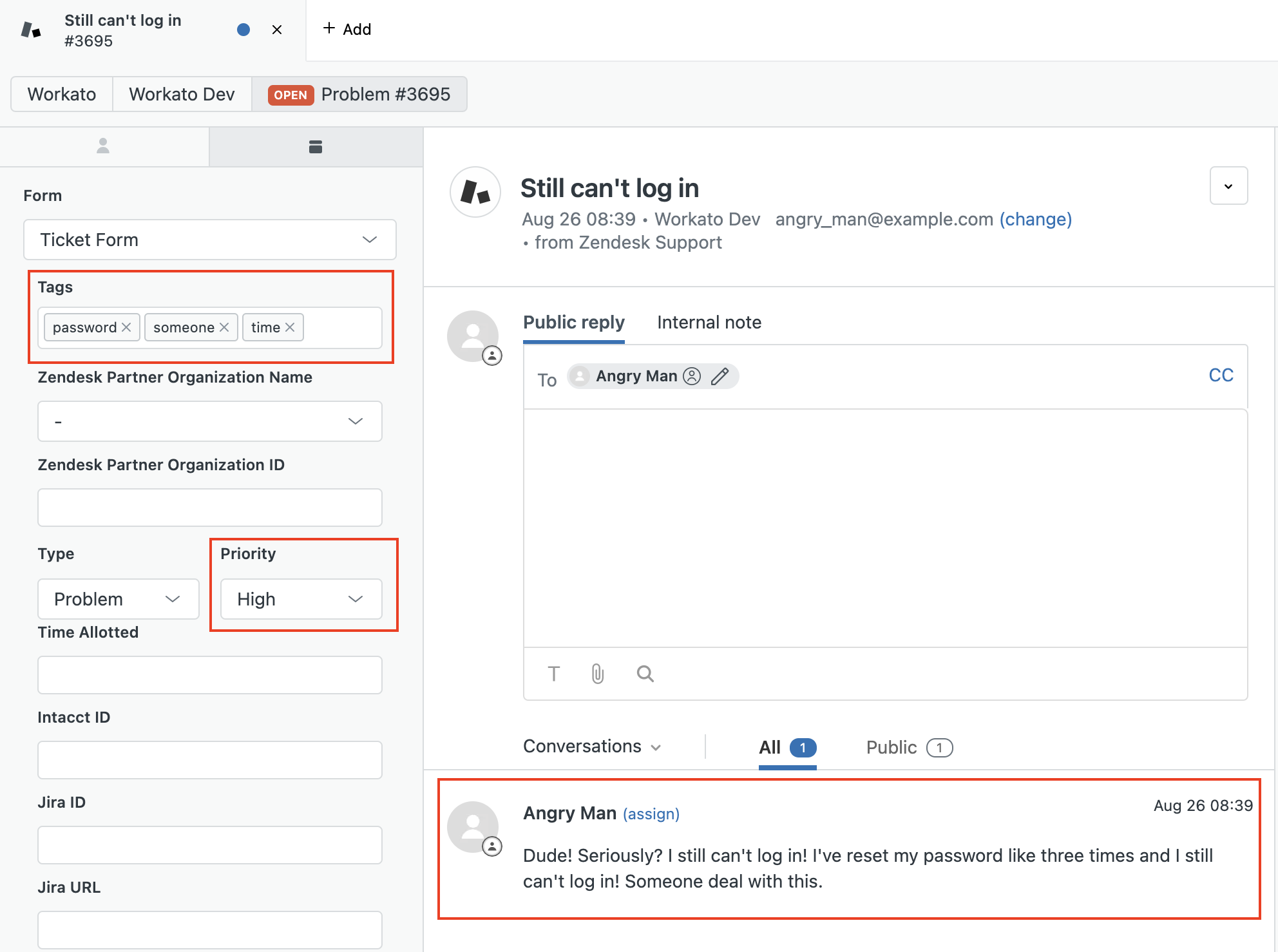
You can see that we’ve identified the tone of the email as angry and set the appropriate priority. Our keyword analysis successfully identified “password” as a keyword. In a real-world use case we could tweak our model to exclude less relevant keywords with additional training.
What next?
This example is a little basic for the real-world, but hopefully it gives you a few ideas about the potential for unstructured data in your workflows. The HTTP connector can hook you up to any API endpoint, so it works just as well with enterprise grade machine learning, OCR and NLP tools as with these free ones.
Resources
If you’d like to experiment with this example, you can get the full recipe from the Community Library.