

Enterprise platforms for managing accounts, transactions and employees often output staggering quantities of data. Furthermore, data is often unstructured, or semi-structured. This can cause a lot of frustration when you’re trying to sync data between systems. You might only need a few key pieces of data from a large payload. You want to create a simple 1:1 mapping from one app to another, but instead you’re crawling though a tangled data tree, sifting through lists of lists, trying to pluck out the information you actually need.
While a visual building experience makes automations easier to build and maintain, complex data mapping can sometimes be simplified by adding just a little code to the mix.
As an example, say we want to create a table of employee records in Snowflake for analytics and comms. We need just a single table with a few simple columns:
- Employee ID
- Birthdate
- First Name
- Last Name
- Home Address (1 column per address part)
- Work Address (1 column per address part)
- Home Email
- Work Email
- Home Phone
- Work Phone
Tracking down the data
The employee data we need lives in Workday, and we can easily query for a list of all workers. However, the records returned by Workday are much more complex than the directory we’re trying to create, and some details are harder to find than others:
- Some data, like the Employee ID and Birthdate, sits at or near the top level of the employee record. These are simple to select and map.

- Other data is structured, but deeply nested. For example, the employee name is buried five levels deep, and there are separate records for preferred name and legal name. We could map each to different columns, but for communications and analytics, we only need the preferred name.

- Contact data, like email, phone number and address is semi-structured. For example, the record contains not a single address, but a list. Each address in the list contains a list of “Usage data” objects. Each usage data object contains a list of “Type data” objects. This final object is what identifies the address as a “work” or “home” address. Every address in the list could potentially be a work address, a home address, both, or neither.
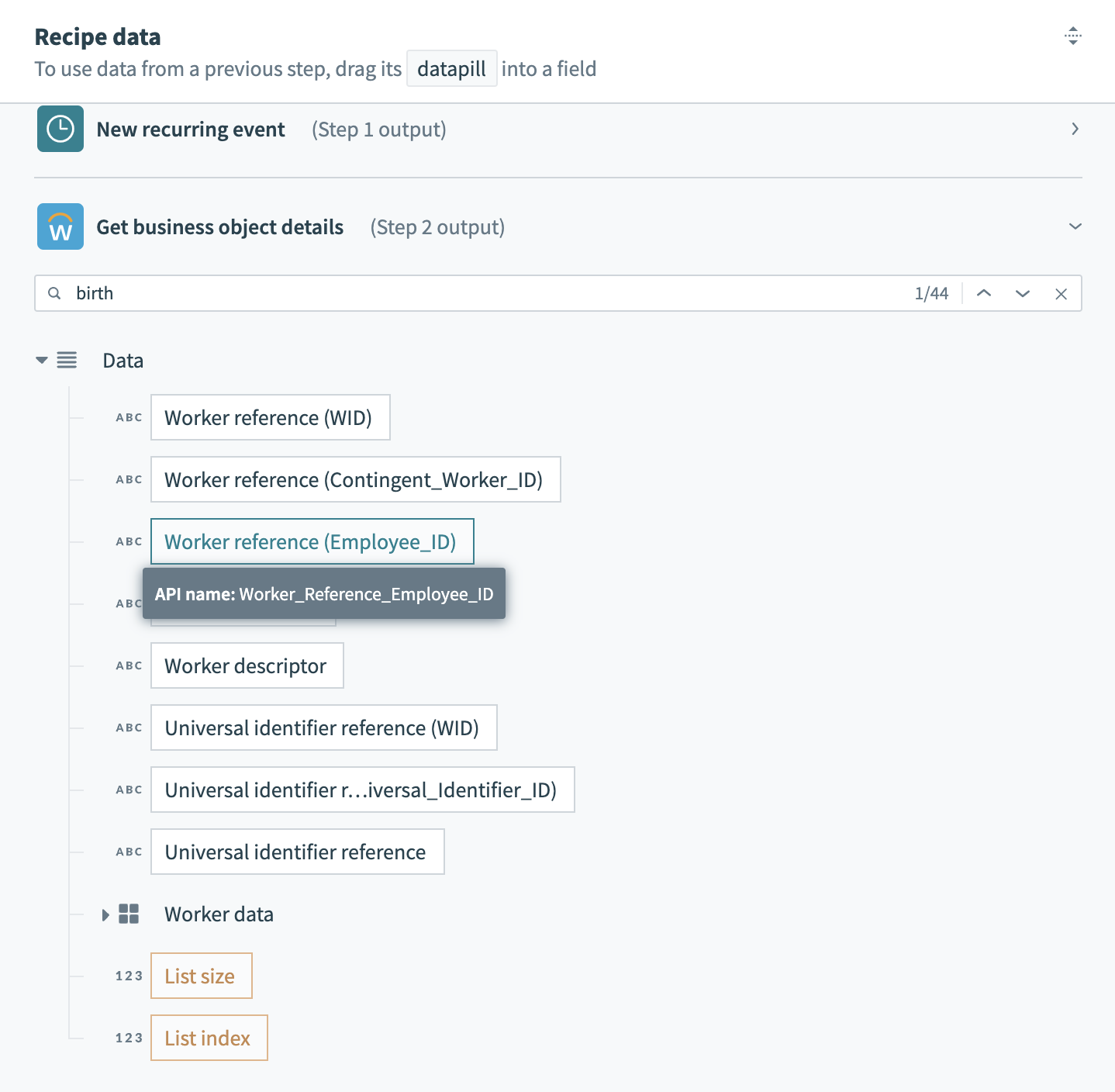
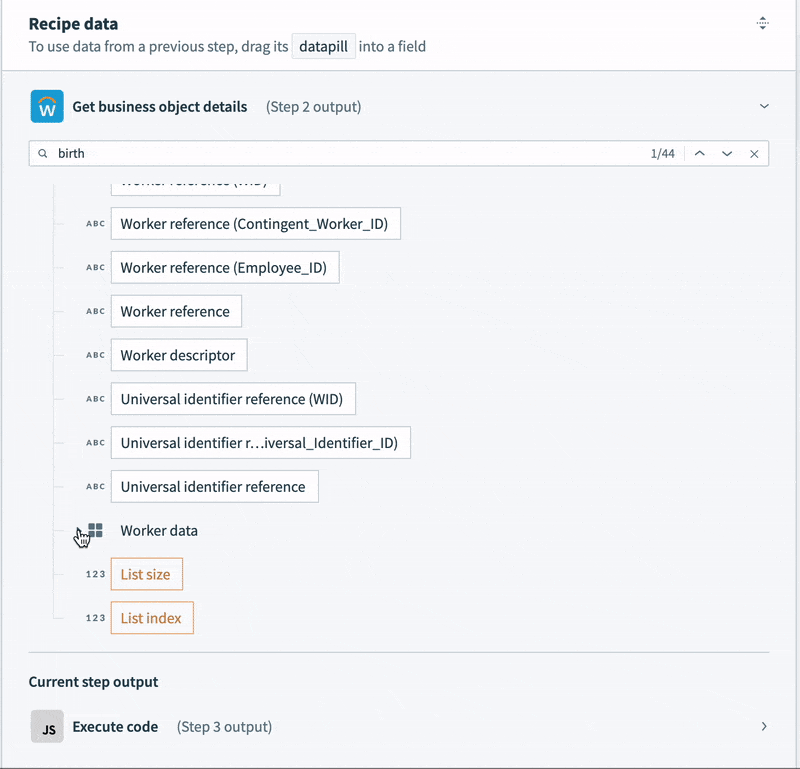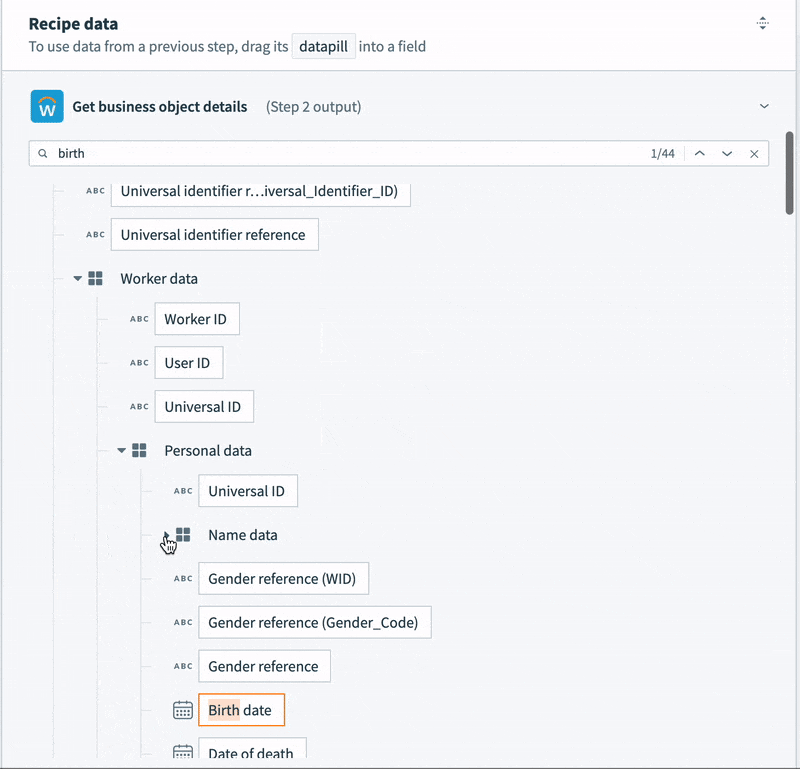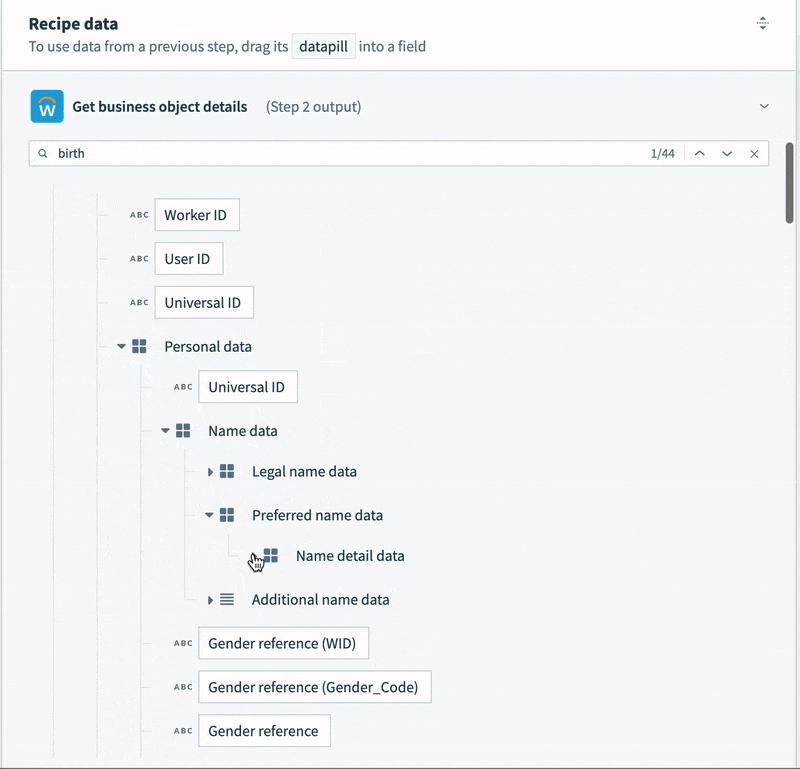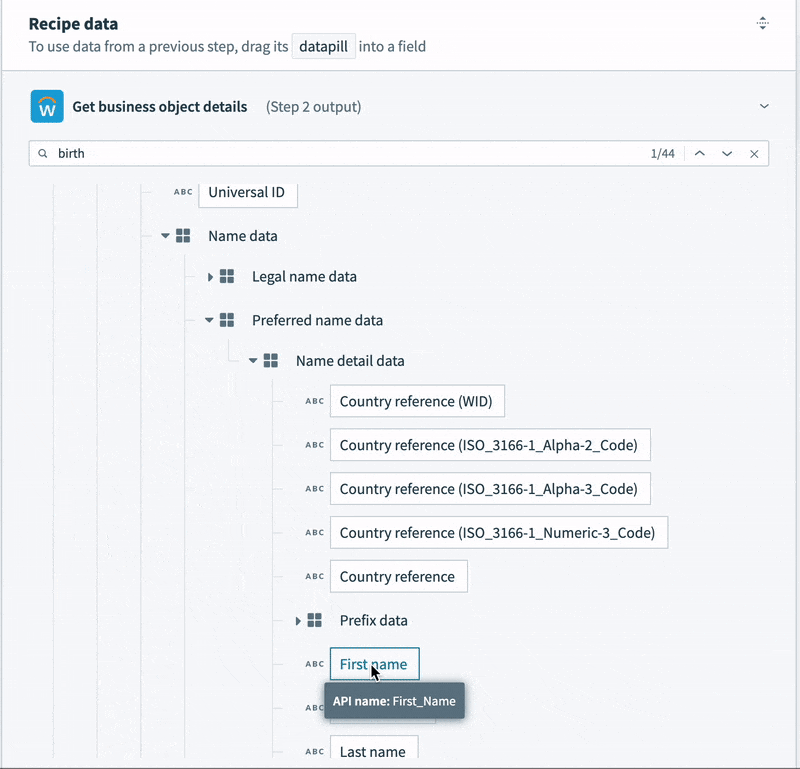
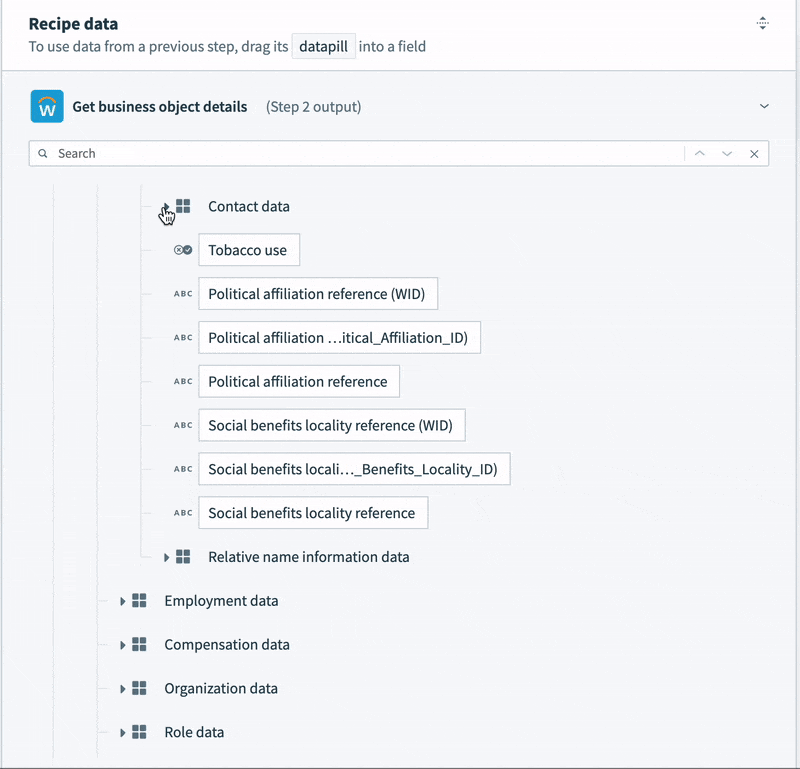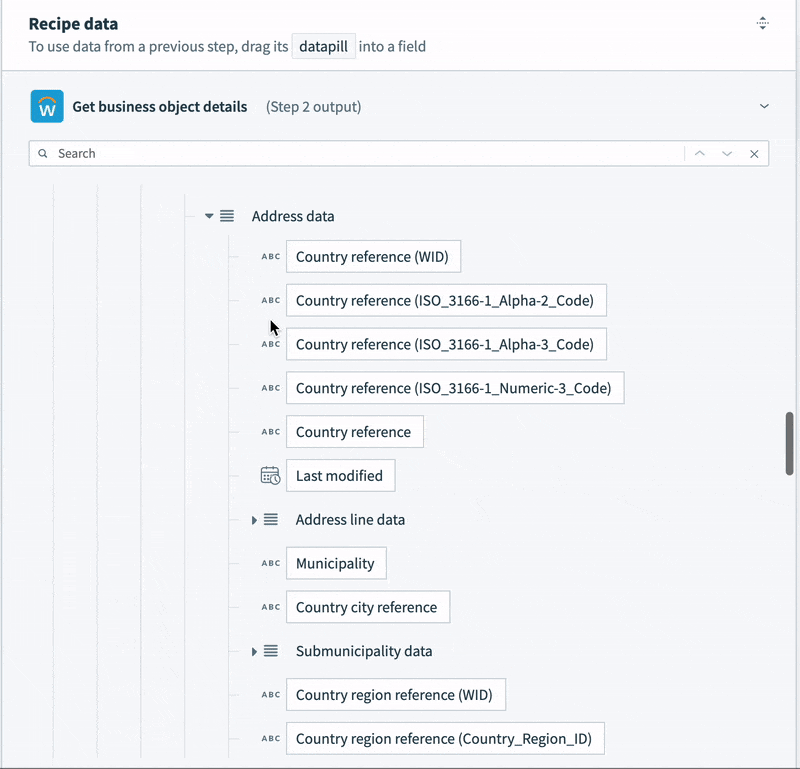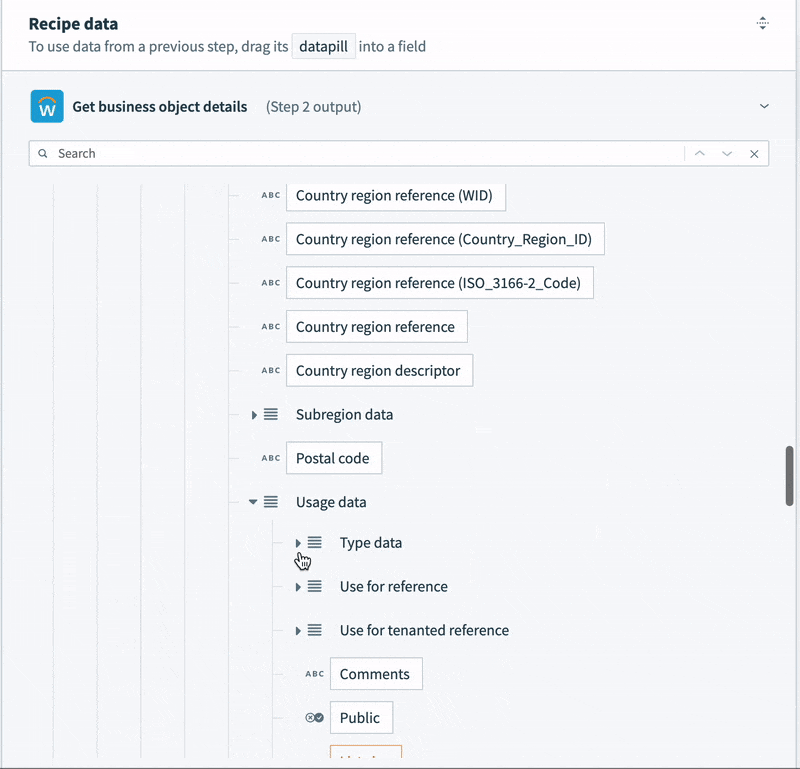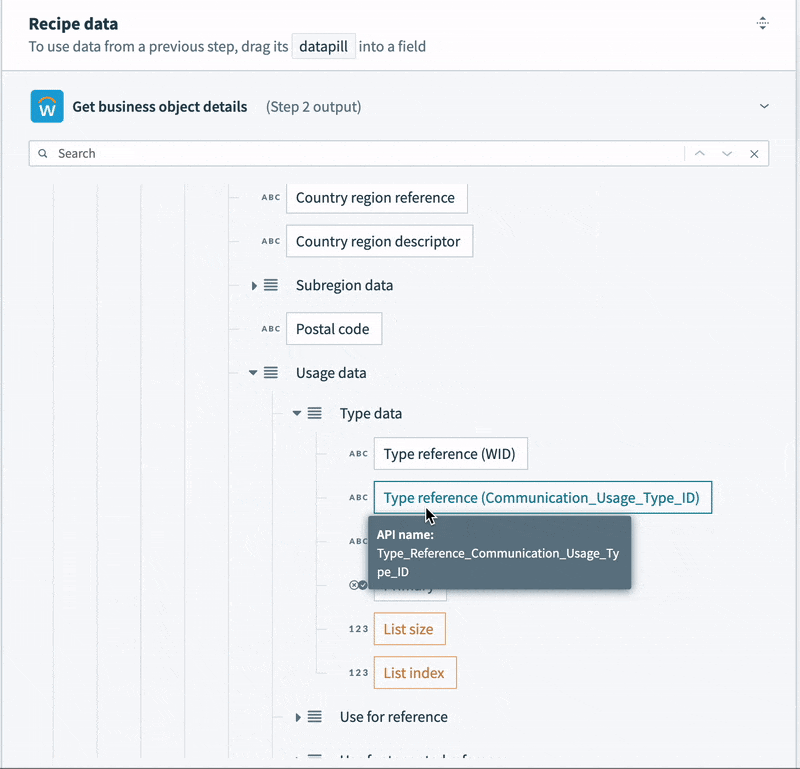
To tame this semi-structured contact data into something we can map to a simple table, we’re going to need some slightly tricky logic. We can’t just select a home address. We need to work through each address in the list, and the additional nested lists inside the address, to determine if it is a home address. Then, we can map it to our home address columns.
A little code can go a long way
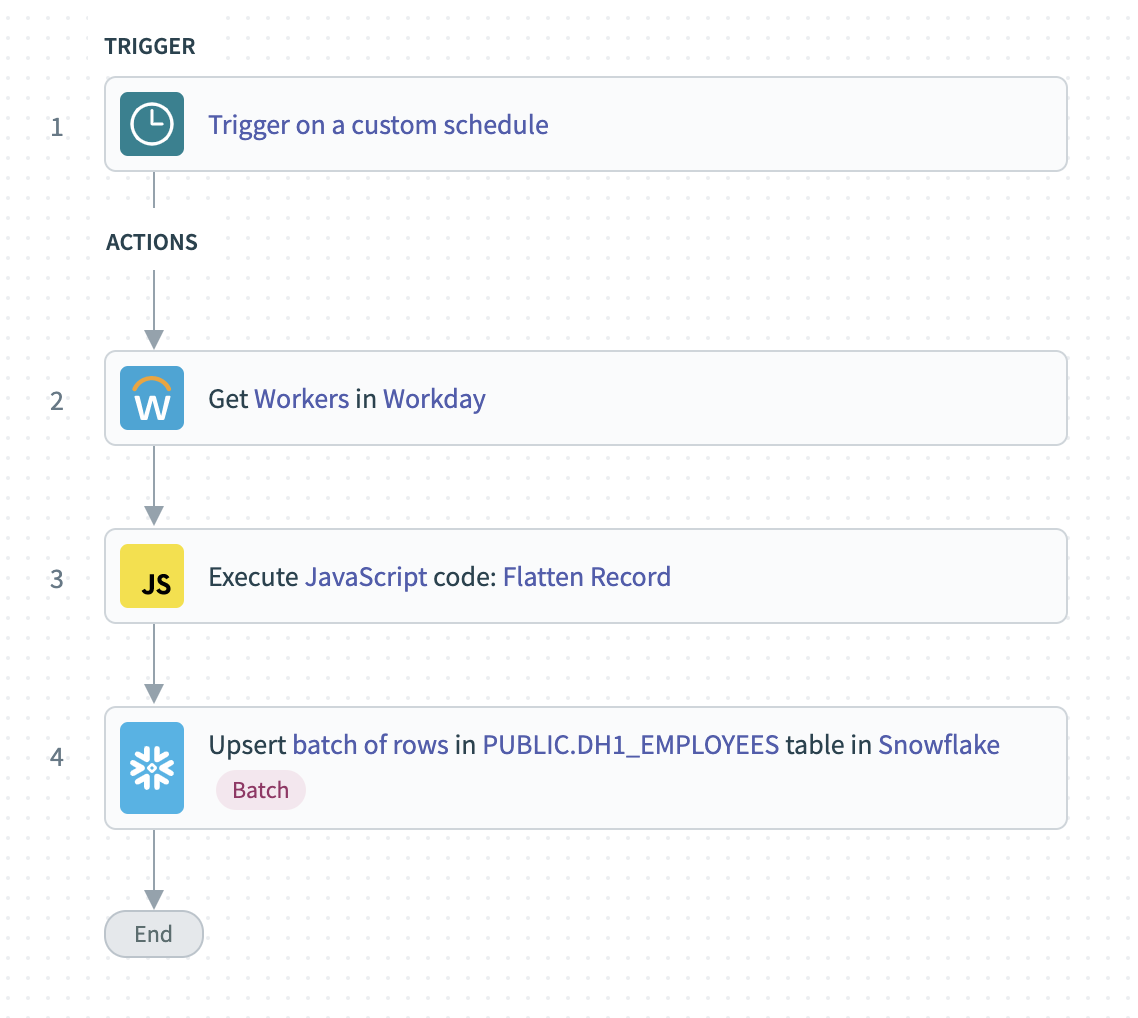
This is a great example of a time when leaning into the “low-code” of our low-code/no-code approach can help to keep things simple. With a JavaScript action, we can write custom logic to “flatten” the data we need from each employee record in a single row. Then, we can take care of all data mapping in a single step. The final recipe will look like this:
Importantly, even though we are going to write a little code here, we don’t need to worry about:
- Hosting the function
- Setting up API gateways or any other method for piping raw data to the function
- Figuring out how to move the output of the function to its final destination
- Managing performance and scale
The platform takes care of all of this for us. All we need to think about is the problem we’re trying to solve.
How to do it
Define input and output
The first step to using the Javascript action is to pass it some input, and then define the shape of the output we expect it to produce. This will let us use the output in later steps.
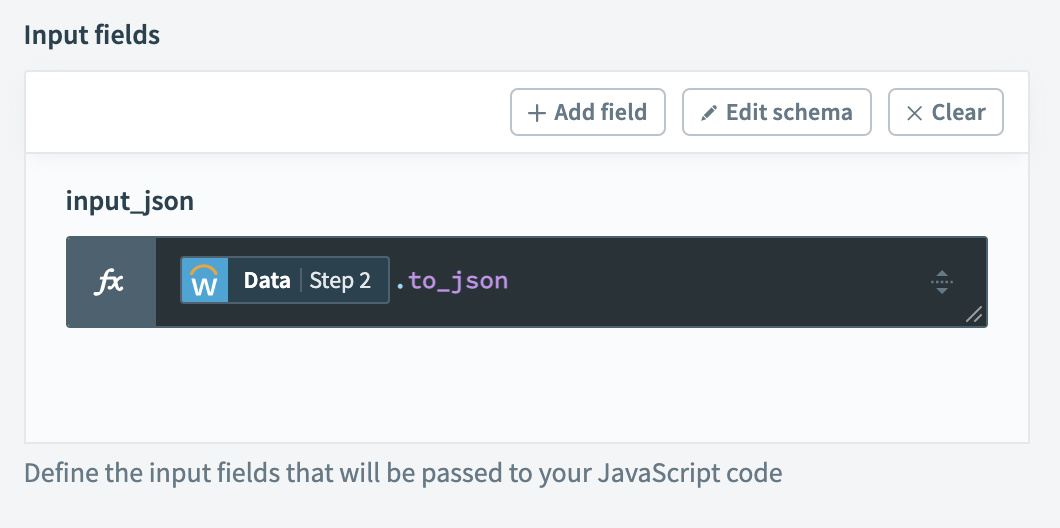
The input is simply the list of records from the Workday query. We can use a formula to convert them to JSON format:
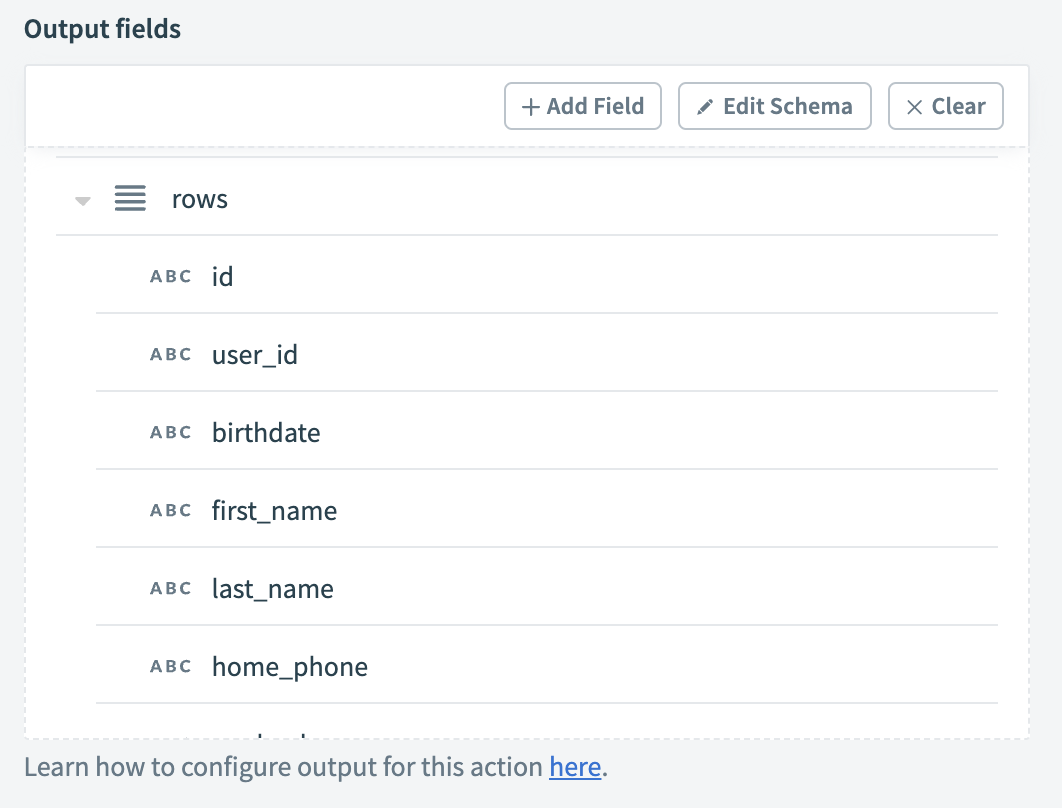
For the output, we can define a simple list of rows, and the fields we need for each row:
Outline a JavaScript function
The basic outline of the JavaScript action defines a main function which:
- Takes and parses a JSON array
- Processes each object in the array into a single row
- Returns an array of all rows
Next, we need to define how to process each employee record, by filling in the createRecord function.
Map simple fields
We’ll start by grabbing the simple fields and mapping them to the appropriate columns. Some of these fields are nested more deeply than others, but there’s always a single path to the data we need, so we can map them in one line.
Map semi-structured data
There are three key types of semi-structured data we need from each employee record:
- Address
- Phone number
Let’s look at the Address as an example. We have an unknown number of possible addresses, and we need to narrow them down to a maximum of 2: work and home. But, to find out the type of an address, we need to loop through two nested lists. So, for each address, we need to:
- Store the relevant parts of the address as variables
- Examine each
Type_Dataobject inside eachUsage_Dataobject- If at least one type record matches
"HOME", map the address to thehome_addresscolumns - If at least one type record matches
"WORK", map the address to thework_addresscolumns.
- If at least one type record matches
This will leave us with a maximum of one home address, and one home address. It also allows for the possibility that a single address can be both types. We can follow the same basic pattern for email and phone data.
Handle multiple matching records
For best results, we need to refine our approach a little further. Workday’s data structure doesn’t guarantee that there will be only one address of each type. If an employee has been with the company a long time, there might be records of two or more “home” addresses. For the directory, we need to make sure that we always have the most up-to-date address.
Fortunately, part of each address is a last updated field. We can use this field to resolve any conflicts. To do this, we need to:
- Add two extra columns to our row:
work_address_last_modifiedandhome_address_last_modified. These columns aren’t part of the output we defined for the JavaScript action. We’ll only use them to resolve conflicts. - As we process each address, check each of our two new columns for an existing value. If none exists, we’ll create a temporary value of
0, sinceundefinedvalues can’t easily be compared in JavaScript. - Update the conditional logic to check not only if the address type matches
"WORK"or"HOME", but also if the last updated date of the current address is later than the current value. If it is, we’ll overwrite the columns with the newer data.
We’re now all set to map Workday’s complex semi-structured employee records to a simple, structured table. By implementing some basic logic in our code, we’ve made sure that we’ll always have the best and most up-to-date data available for each employee.
Where to from here?
We now have a recipe that takes a huge and complicated semi-structured employee record and wrangles it into a simple format that we can use for employee analytics and communications.
What else could we do with this automation? One possibility is to perform some quality control on the contact data. USPS provides an address verification service that can check the validity of a US address against its own database. We could use the community connector for this service to check each address and send a notification to the HR team to follow up on any invalid ones.
We could also check each row for any missing values. Don’t have a home address on file? Missing a birthday? Automate an email prompt for the employee to provide the missing data.
Resources
If you’d like to play around a little more with this example, check out:
- The finished recipe in our community library
- The complete code for the JavaScript action
- A sample JSON employee record from Workday