
We have introduced SQL Server Replication with the new replicate action in the SQL Server connector. As a result, you can now create resilient data pipelines that automatically adapt to schema changes. This also helps to eliminate stress about losing data or keeping up with changes.
Setting up and maintaining data pipelines is hard. With the rising adoption of SaaS applications, the ability of a data pipeline to adapt to changing source schemas is increasingly important.
Also read: Automating SaaS management for cost savings
How does the new SQL Server replication feature help you?
With the new SQL Server replication feature, mismatched schemas between the data source and SQL Server will be automatically reconciled. For you, it means greater convenience and less worry because your data pipelines will be automatically and efficiently maintained. Even as the schema changes in the source system, you can rest assured knowing that data will not be lost.
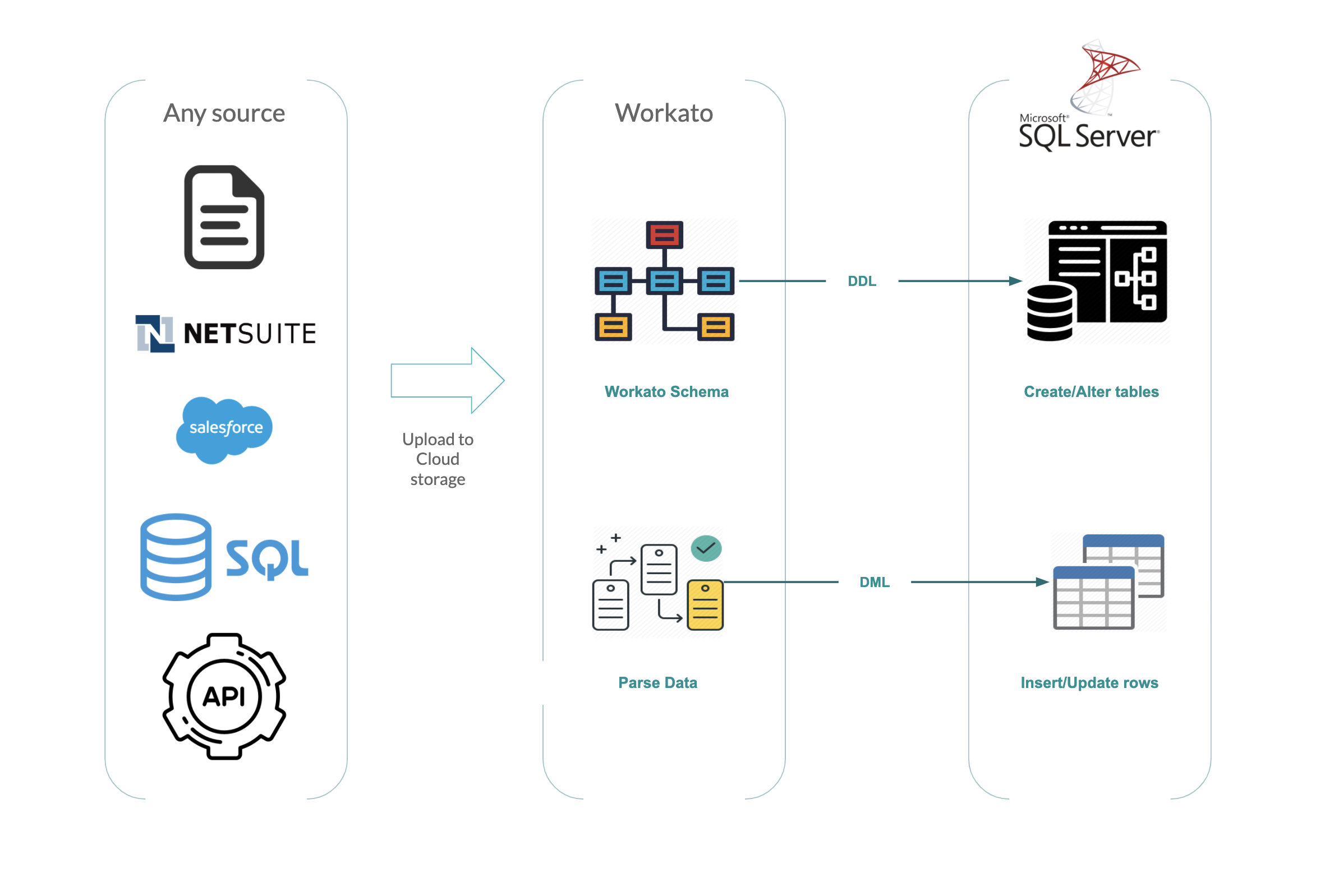
Replication in Workato’s SQL Server Connector ensures that changes to schemas in source systems are automatically reflected in SQL Server
Watch this video to see the SQL Server replication feature in action:
Examples of automations that companies are implementing with the SQL Server replication feature.
Set up object definition automatically — Faster initial setup and load
Setting up a new data pipeline to SQL Server usually requires an infrastructure manager or someone in IT to set up the object definition for each object. This can take weeks of work, especially if you have to set up hundreds of objects, and mistakes can be made if done manually.
The SQL Server replication feature enables you to set up the object definitions automatically in SQL Server based on the schema in the source application. For apps with a ton of objects, like NetSuite, this feature can save a ton of effort and headache by automating the table creation for each object as well as performing the initial data load at the same time.
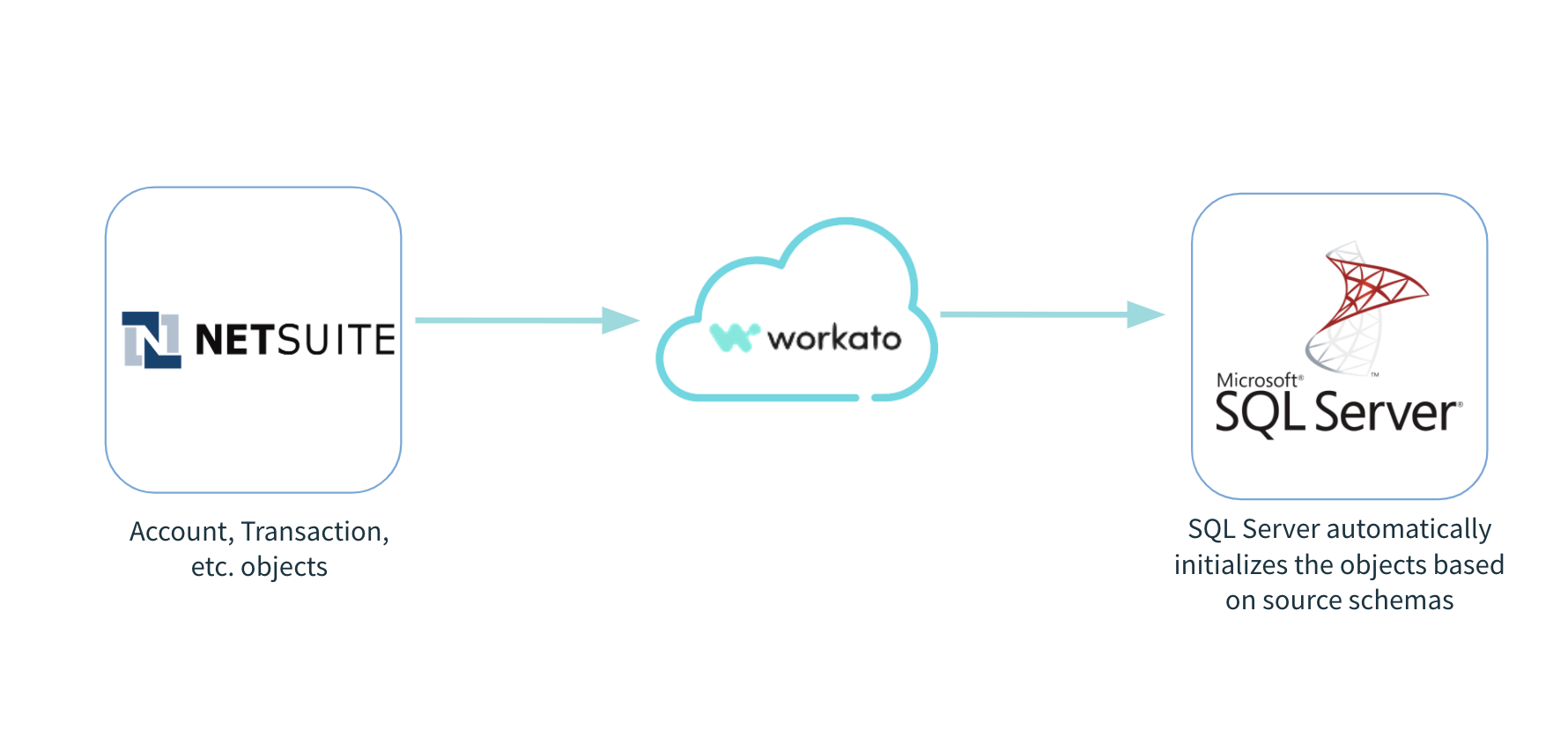
Performing an initial load of data into SQL Server from apps like NetSuite are fast with automatic replication automatically initializing the objects in SQL Server
Easier maintenance of data pipelines — Set it and forget it
Once a data pipeline is set up, maintaining the pipeline is an ongoing challenge. If source systems are fairly static, the workload is manageable.
With the rise of SaaS applications, however, source schemas are in constant flux. Admins for apps like Salesforce are constantly adding or changing fields, which can break an integration or cause data to be missed until the pipeline is updated.
Now you never have to worry about lost data again. As new fields are added in Salesforce, the replicate rows action automatically detects schema changes and updates the corresponding SQL Server tables. It also deduplicates rows and ensures the two systems remain in sync.
Also, to safeguard sensitive data, you can choose which fields you want to exclude from the data load, ensuring that the data of the company will not be accidentally divulged.
Also read: How to protective sensitive data with masking
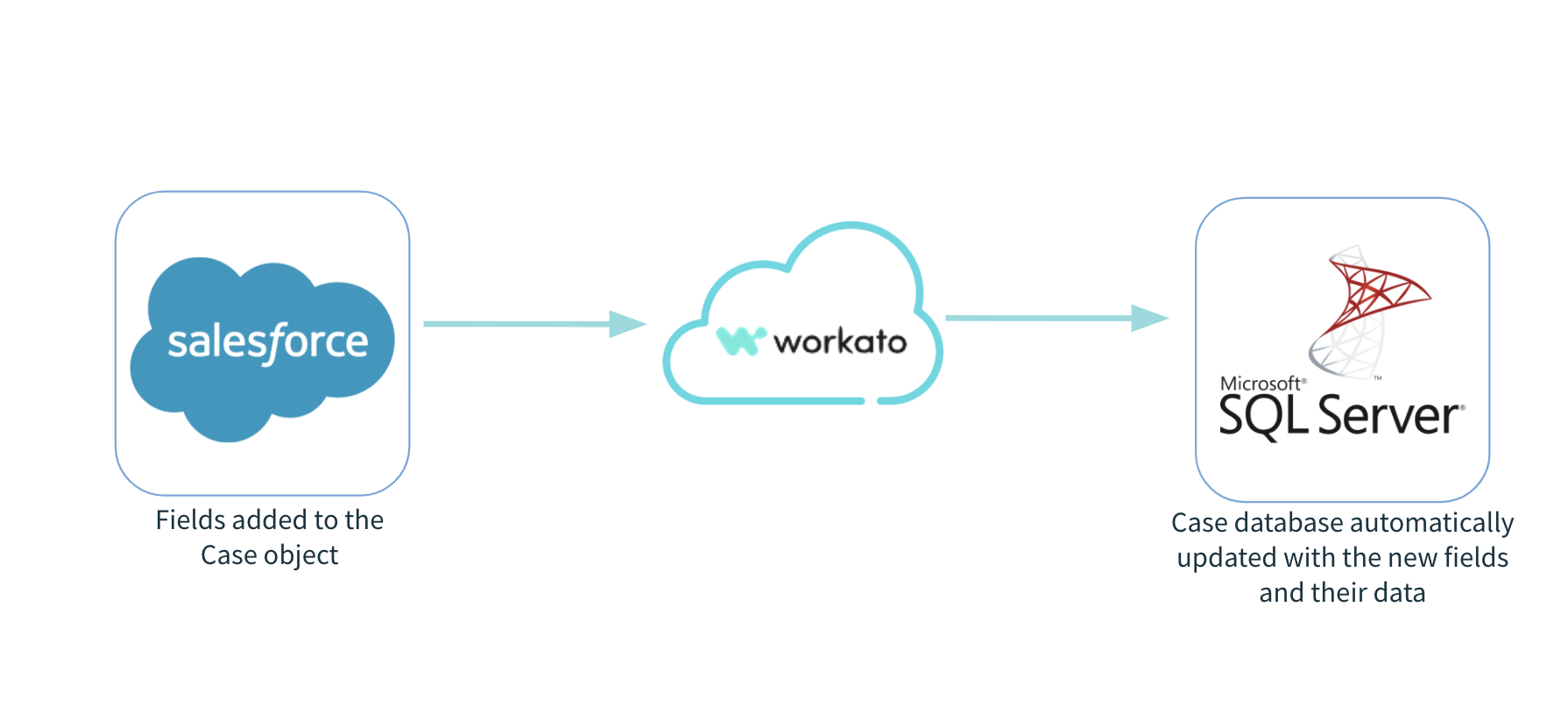
Fields added to the source schema, like new fields on the case object in salesforce, will be automatically detected and added to SQL Server so no data is lost
How it works:
1) Initial setup for the data pipeline
Initially set up the data pipeline with the “Replicate rows” action in the SQL Server connector in the Action step. Note that the “Replicate Rows” action processes data in batches.
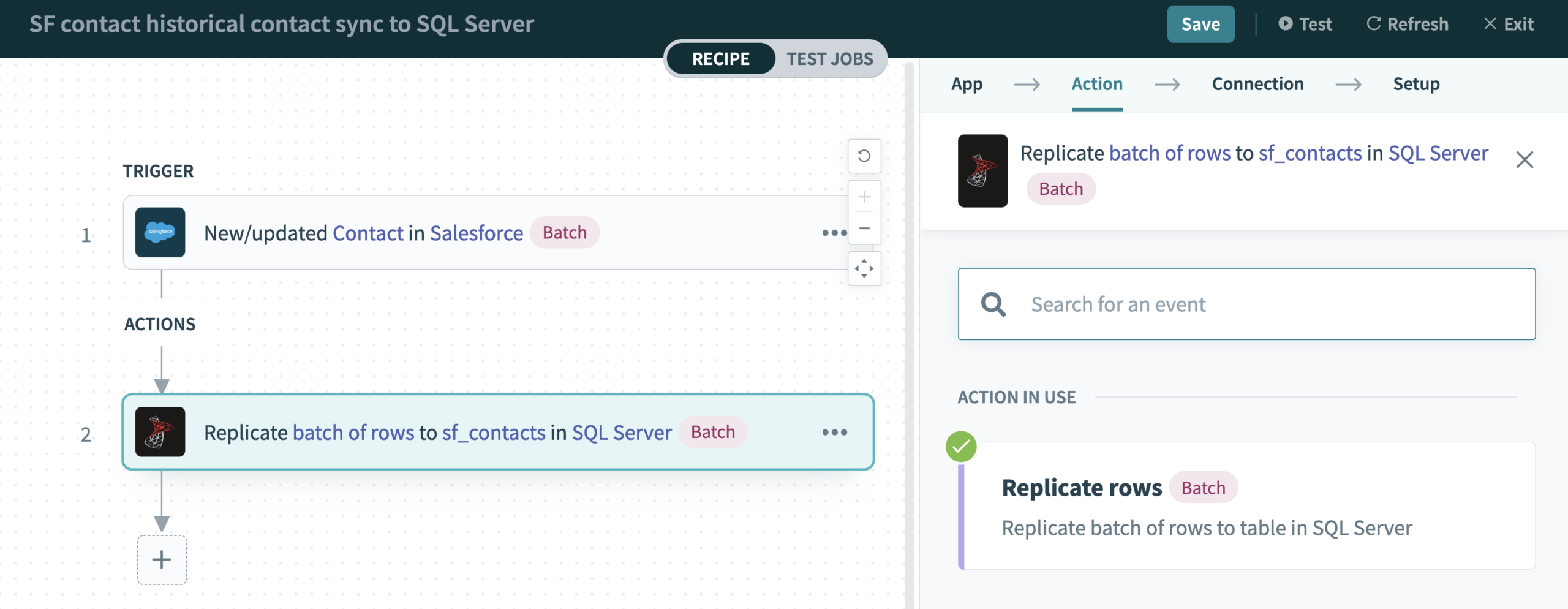
The “Replicate rows” action makes it easy to copy full tables into SQL Server and ensures data is preserved when changes are made to the source schema.
When you run the recipe job for the first time, Workato automatically reads the object definition (e.g. contact object in Salesforce in the example above). It then creates a table in SQL Server based on the following information you provide in the Setup step below:
-
- Table Name: A unique table name that will be the destination for the replicated data. If there is no existing table, Workato automatically creates the table with the right field types.
- Unique Key: The unique key in the table that will be used to determine new/updated data for UPSERT operations.
- Flatten Columns: When replicating an object that may have a hierarchical data structure (e.g. address columns for an account object), you have the option to replicate the data as is or flatten the structure to create a separate column for each element.
- For example, when you flatten an Address object: Address Line 1, Address Line 2, City, State, Zip, and Country will be created as separate columns.
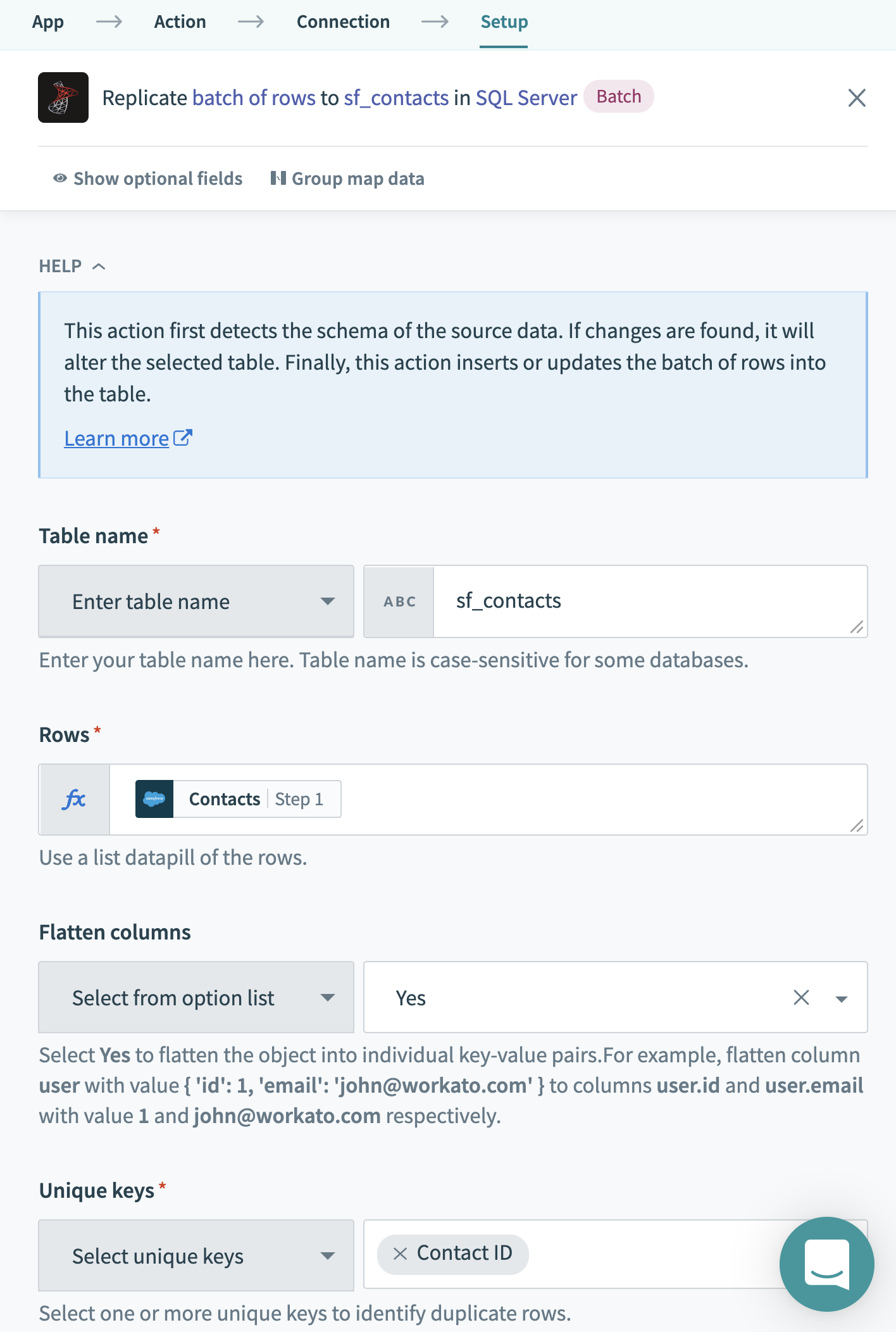
The SQL Server connector makes it easy to perform powerful transformations like “Flatten columns”
2) Capturing changed data and schema
- When changed data is detected in the data source, Workato first inspects the new object definition against the existing SQL Server table schema.
- When mismatches in source schema object and the table definition in SQL Server are detected, the recipe job will alter the table definition to match that of the source object.
- Next, the recipe job will sync the data for the updated object definitions to ensure no data or schema changes are lost.
To find out more, read the full documentation on the Replicate action in the SQL server.