

The need for batch processing
Processing data in batches is an efficient way of moving large volumes of data across systems. Typically, batching is useful in business processes that require data collection over a period of time, migration of historical data, or an initial loading of data into a new system. The common elements of such business process are:
- Large number of transactions (e.g. millions/day)
- Low frequency of operations: one-time or periodic occurrences (hourly, daily, weekly, monthly, etc.)
A few examples:
- Loading transactional data: orders data from Salesforce or payment data from Stripe into Enterprise Data Warehouse (EDW) for BI.
- Importing data from files, such as lead data from a CSV, billing data from partners, or sales data from online stores into a CRM (e.g. Salesforce), financial (e.g. NetSuite), or ERP application (e.g. SAP).
- Data migration, such as migrating opportunities, orders, contacts, leads, accounts, and product data from a legacy CRM to Salesforce.
- Initial Load: loading product skews and hierarchy into CRM or financial applications.
Workato’s batch processing is designed to solve those use cases.
Understanding batch processing in Workato
Whenever a Workato recipe detects a trigger event (e.g. new account is created in Salesforce), it executes a job. When moving data from one application to another, a job looks like this:
Typically, a single job processes one row of data or one record. Batching enables you to process multiple rows of data or multiple records with just one job. Here’s an example:
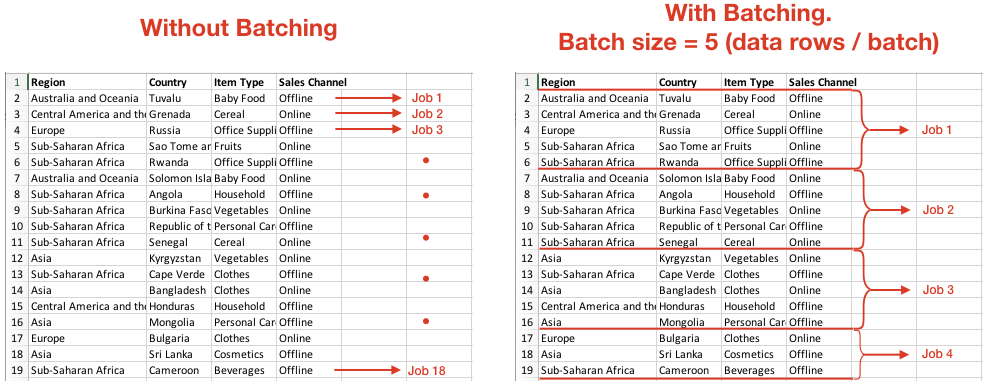
Use batching for faster processing
When a job runs, a large amount of time is wasted waiting for responses from the source app’s API and the destination app’s API.
By increasing the batch size, the number of jobs is reduced. By reducing the number of jobs and increasing the number of rows of data processed in each job, you can increase the overall throughput of the job. Needless to say, the total run time decreases significantly due to the reduction in wait time for API responses.
The following chart shows how different batch sizes can reduce running time when Workato transfers 100,000 lines of data.
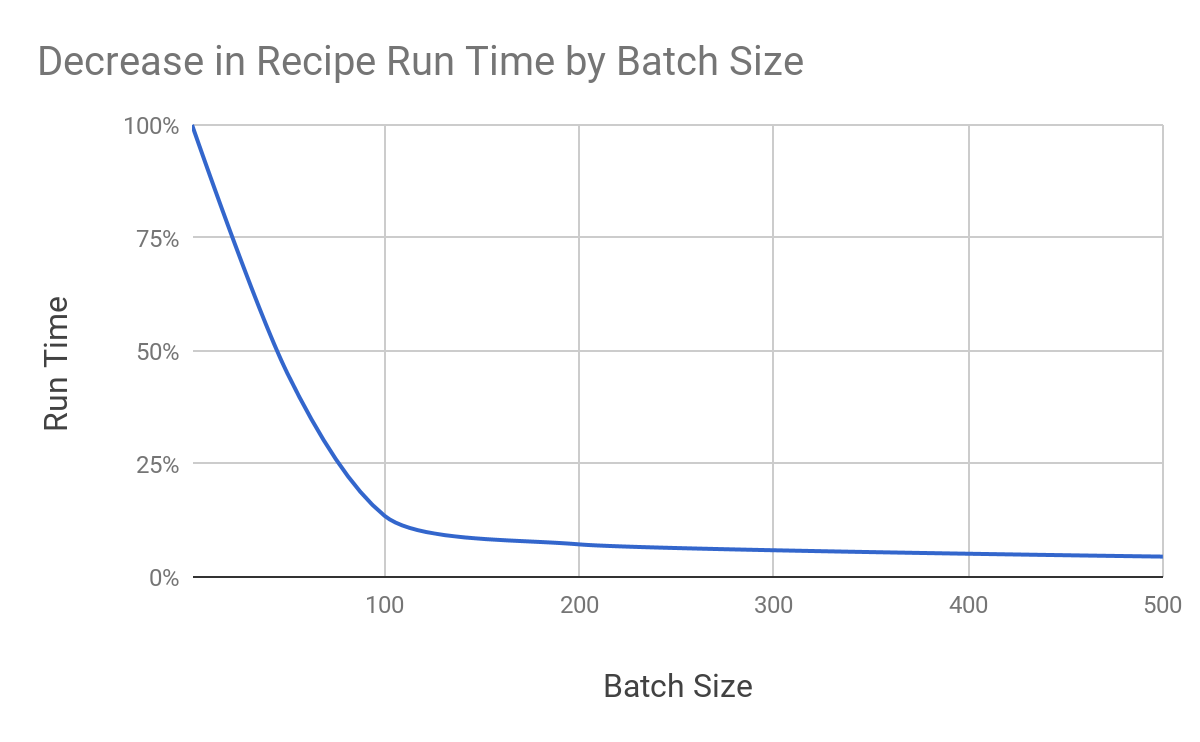
Getting started with batching is easy
Batching is available on Workato for major enterprise apps, databases, and file storage systems like Salesforce, SQL Server, Oracle, Redshift, Box, Dropbox, SFTP, and more. You’ll see a “BATCH” label next to any trigger or action that supports batching.
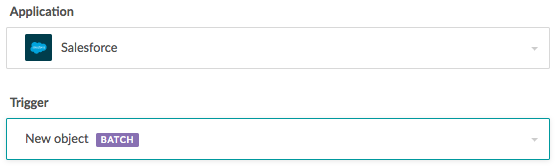
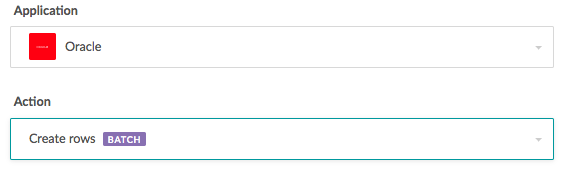
Let’s look at a simple use case to see how you can build a Workato recipe with batching to handle a data transfer.
Use case: Daily import of sales records to analytics database
Quite often in an enterprise, data—often contained in CSV files—must move from one department’s system to another on a daily basis. In this case, it is daily sales records of up to 100,000 rows, which are stored in Box. The data will need to be imported into a Redshift database for analytics purposes.

CSV File of Daily Sales Records
Traditional integration projects may require significant development resources in order to automate this workflow. With Workato, it takes 15 minutes to setup this simple recipe to move the data.
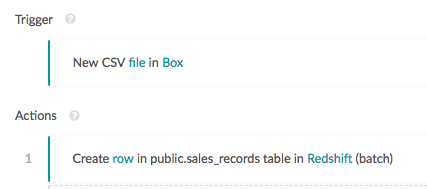
Any time a new CSV file is uploaded into Box, Workato will read the files and import it into Redshift table called “public.sales_records”. The field mapping is as simple as drag-and-drop:
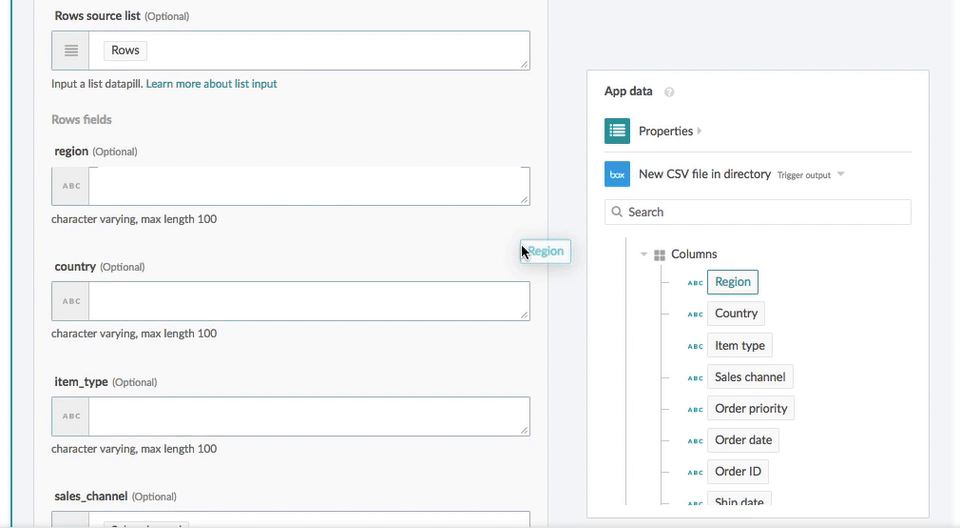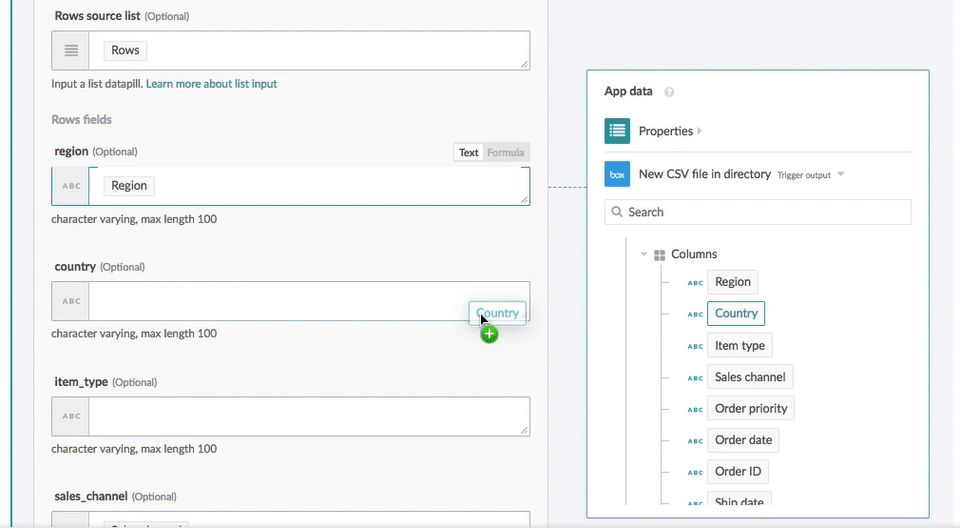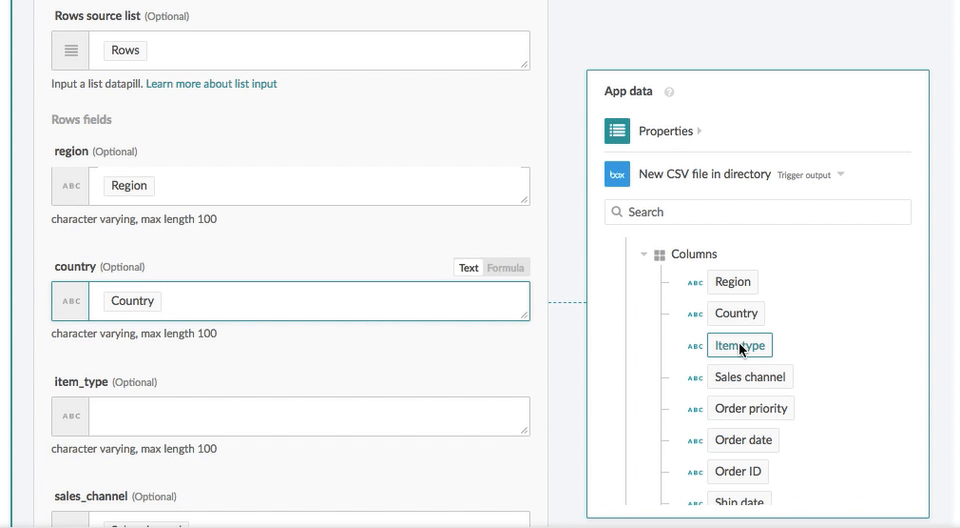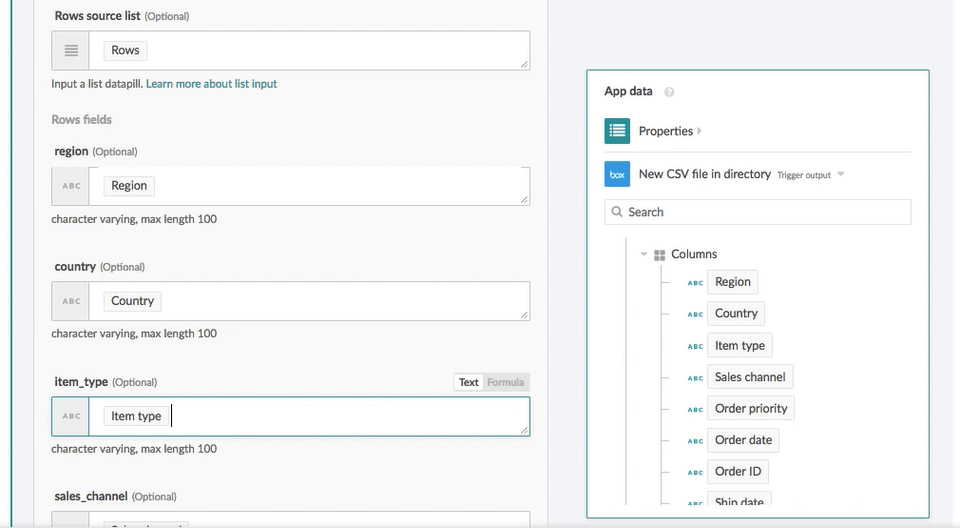
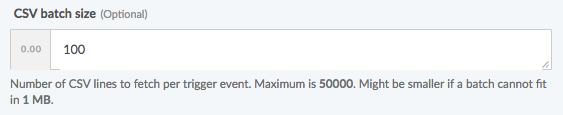
You can specify the batch size to speed up the data import.
Once you’re finished customizing the recipe, set it to active and forget it! Workato will diligently transfer your data every day and notify you when errors occur.
Feel free to try out the recipe here. You can even download these sample CSV files to test it with!
What’s next?
Now that you have had an idea of how batching can speed up your workflows, why not building a few recipes of your own? A good place to start is our Community Recipes page, with a variety of recipes built by our users. Workato docs and the Workato Success Center can also help you along the way.
And keep an eye out for the rest of this article series, where we’ll dig deeper into advanced techniques for managing batching and increasing your data throughput. Stay tuned!