分散トランザクションは途中で失敗することがあります。決済は成功したがSalesforceの更新がタイムアウトする。顧客は支払い済みだが、複数のシステムの状態が一致しない。
本番環境ではこのような状況は頻繁に発生します。システムのタイムアウト、通信の切断、想定外の入力など、分散システムでは一部の処理が成功し、別の処理が失敗することがあり、全システムの整合性を回復するためにリカバリー処理が必要になります。
では、MCPツールを組み合わせたワークフローではどうなるのでしょうか。LLMが複数ステップのワークフローをオーケストレーションし、再試行や同じツールの複数回呼び出しが行われる場合、それぞれのツールが部分的な失敗の発生ポイントになります。誰が状態の整合性を回復するのか。それはこれまで議論してきた責務分離の考え方とどう関係するのか。
冪等性は再試行を処理します。エラーハンドリングは失敗を検知します。しかし、一部成功した状態には対応できません。リカバリーには、何が成功し、どう元に戻すかを把握する仕組みが必要です。
これまでの記事では、Composable Skill設計やServerless実行について説明しました。本記事では、信頼性の高い実行を行っても状態不整合が発生する場合にどう対応するかを解説します。
リファレンスアーキテクチャ:Dewy Resort
このシリーズでは、ホテル管理システム「Dewy Resort」をリファレンス実装として使用しています。このアーキテクチャは複数のシステムにまたがります。
Salesforce
顧客情報、予約、部屋在庫、商談
Stripe
決済、返金
MCP Tools
これらのシステムをワークフローとして接続するオーケストレーションレイヤー
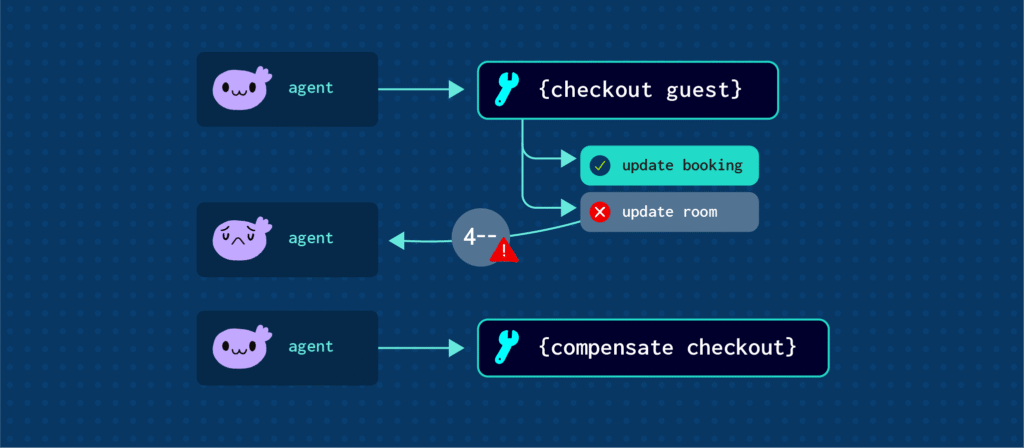
例えば「チェックアウト」という1つの操作で、Stripeでの決済、Salesforceの予約更新、部屋の清掃ステータス更新、商談のクローズなど複数の処理が実行されます。各システムはそれぞれのタイミングでコミットされるため、システム間でトランザクションをまとめてロールバックすることはできません。
問題:トランザクションなしで整合性を保つ
エンタープライズのワークフローでは、本来すべて成功するか、すべてロールバックするかというACIDに近い保証が必要です。しかし、StripeとSalesforceなど複数システムをまたぐトランザクション境界は存在しません。それぞれ独立してコミットされ、独自の失敗パターンを持ちます。
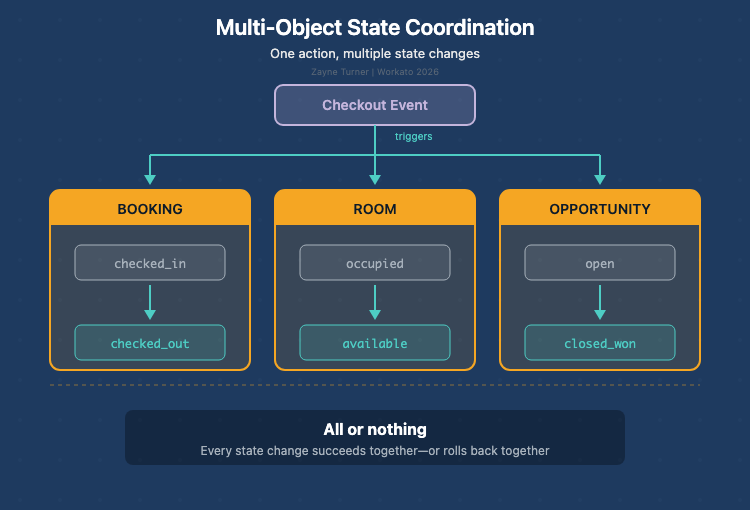
例えば、チェックアウト処理では複数のSalesforceオブジェクトが更新されます。
Booking
Room
Opportunity
Bookingが「Checked Out」に変わると、Roomは「Cleaning」、Opportunityは「Closed Won」に変更される必要があります。どこかの更新が失敗すると、複数オブジェクトが不整合な状態になります。さらにStripeの決済はすでに成功している可能性があります。
結果として、顧客は支払い済みだがチェックアウトは完了していない、部屋は再割当できない、売上レポートも誤った状態になる、といった問題が発生します。
システムをたぐトランザクションがない場合、整合性は自分たちで設計する必要があります。

Try/Catchでは解決できない理由
catchブロックはエラーをログに記録して500エラーを返します。しかし、次のケースを区別できません。
支払い前に失敗した → 再試行して問題ない
支払い後に失敗した → 返金が必要
Salesforce更新中に失敗 → 状態確認と整合性回復が必要
従来のエラーハンドリングは成功か失敗かの二択ですが、分散ワークフローでは部分的成功という状態が存在します。リカバリーには、何が成功したのかを把握し、それを元に戻す処理が必要です。
意思決定の配置
このシリーズでは、LLMとバックエンドシステムの責務分離について説明してきました。この考え方はリカバリー処理にも適用できます。誰が補償処理を判断し、誰が補償処理を実行するのか。
これは完全な自動化システムではありません。人間を支援するエージェントです。重要なのは、人間の判断と決定論的な処理をどこに配置するかです。
人間 + LLM
いつ実行するか
どのワークフローを実行するか
バックエンド
どのように実行するか
どの状態遷移を行うか
財務・セキュリティ関連の判断
必ずバックエンド
この責務分離により、システムはテスト可能で監査可能になります。
リカバリーの2つのパターン
部分的失敗のリカバリーには代表的な2つのパターンがあります。
パターン1:補償トランザクション(Sagaパターン)
Sagaパターンでは、複数ステップの処理を、それぞれ逆操作を持つ処理の連続として扱います。
このパターンを使うケース
複数システムにまたがる処理
決済などの金融処理が含まれる
状態整合性が重要
手動リカバリーコストが高い
チェックアウト失敗時の補償処理では次の処理を行います。
決済状態を確認
返金処理
Salesforceの状態を確認して必要なら戻す
設計原則
状態確認してから戻す
金融処理を先に行う
ビジネス識別子を入力として使う
すべてのレイヤーで冪等性を確保する
パターン2:Fail-Fastバリデーション
高コストな処理の前に前提条件を検証し、失敗を防ぐ方法です。
使用するケース
前提条件が破られる可能性がある
決済など非冪等操作がある
エラー内容をユーザーが修正できる
例:複数予約バグ
予約が0件または複数ある場合はエラーを返し、決済処理に進まないようにします。
失敗を補償するより、失敗を防ぐ方が安い。
リカバリー戦略のまとめ
補償トランザクション
決済成功、Salesforce失敗 → 返金
孤立リソース許容
Stripe顧客作成だけ成功 → 再利用
Fail-Fastバリデーション
複数予約 → 決済前にエラー
冪等性付きリトライ
Salesforceタイムアウト → 同一トークンで再試行
結論
MCPはLLMがツールを発見し呼び出す方法を標準化します。しかし、ツールが何を行い、部分的失敗や状態整合性、リカバリーをどう処理するかは、ツールのアーキテクチャ設計の問題です。
Sagaパターンは部分的失敗時の補償トランザクションを提供します。Fail-Fastバリデーションは失敗自体を防ぎます。そして、意思決定の配置を適切に設計することで、システムはテスト可能で監査可能、柔軟なものになります。
これらのアプローチはDewy Resortサンプルアプリケーションで実装されています。StripeとSalesforceの連携、金融処理、状態整合性、補償処理、冪等性管理などが含まれています。MCPは単なるツール呼び出しの仕組みではありません。エンタープライズシステムを安全に動かすためのアーキテクチャ設計そのものです。